
TIP
流程编排可以让系统提供的服务能力做到可视化,业务逻辑一目了然。BPMN图形中支持普通流程图和泳道图
普通流程图:
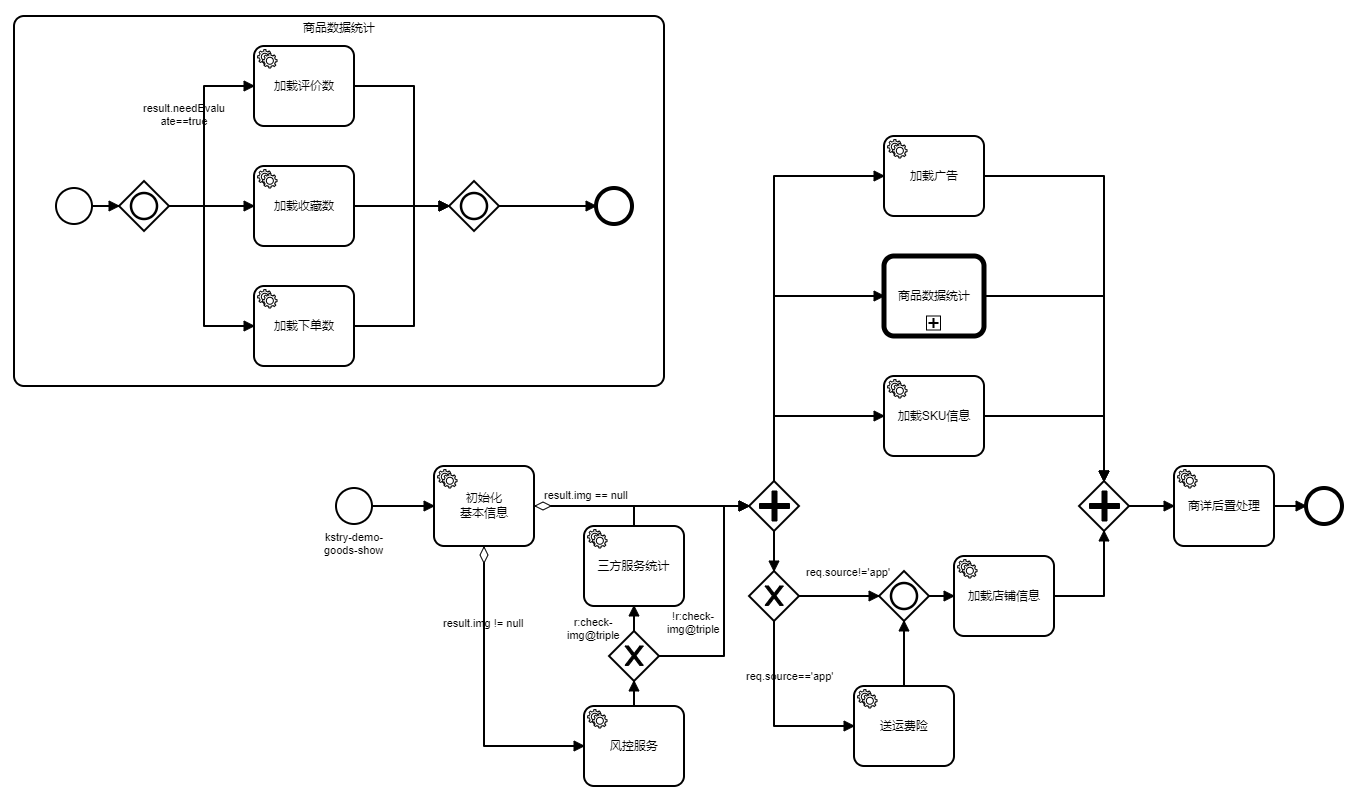
泳道图:
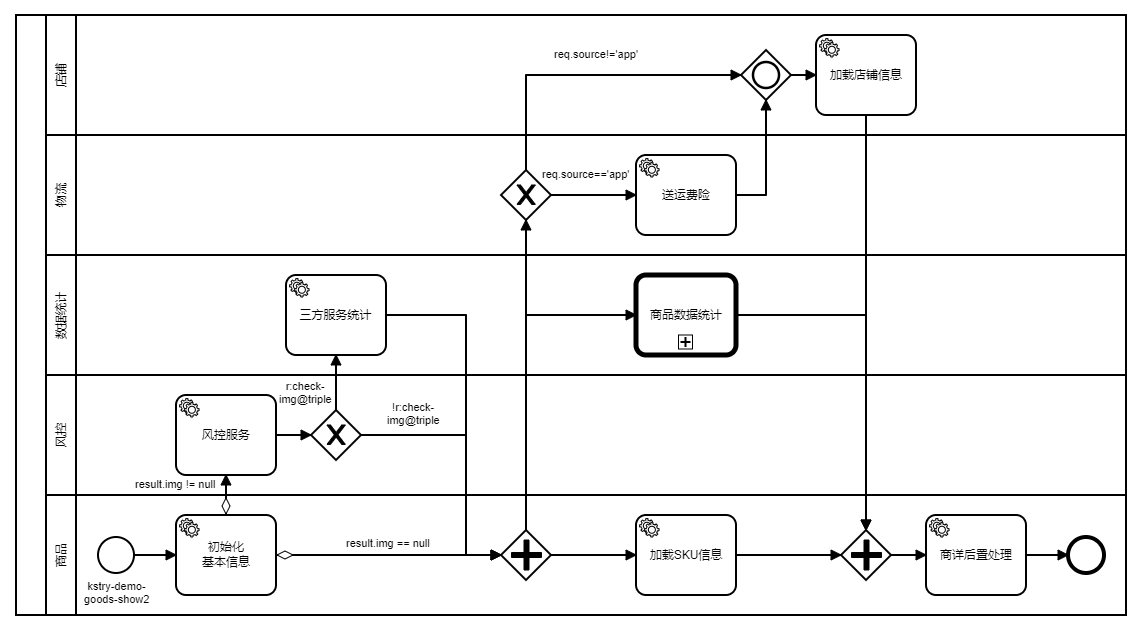
# 2.1 顺序流连线
TIP
Kstry框架沿用了BPMN协议中的概念,流程图中节点与节点之间需要以有向线段连接,以此来定义组件间的前后调用关系。判断是否继续执行下一节点的条件表达式也是定义在这里的
# 2.1.1 使用条件表达式
BPMN图示如下:
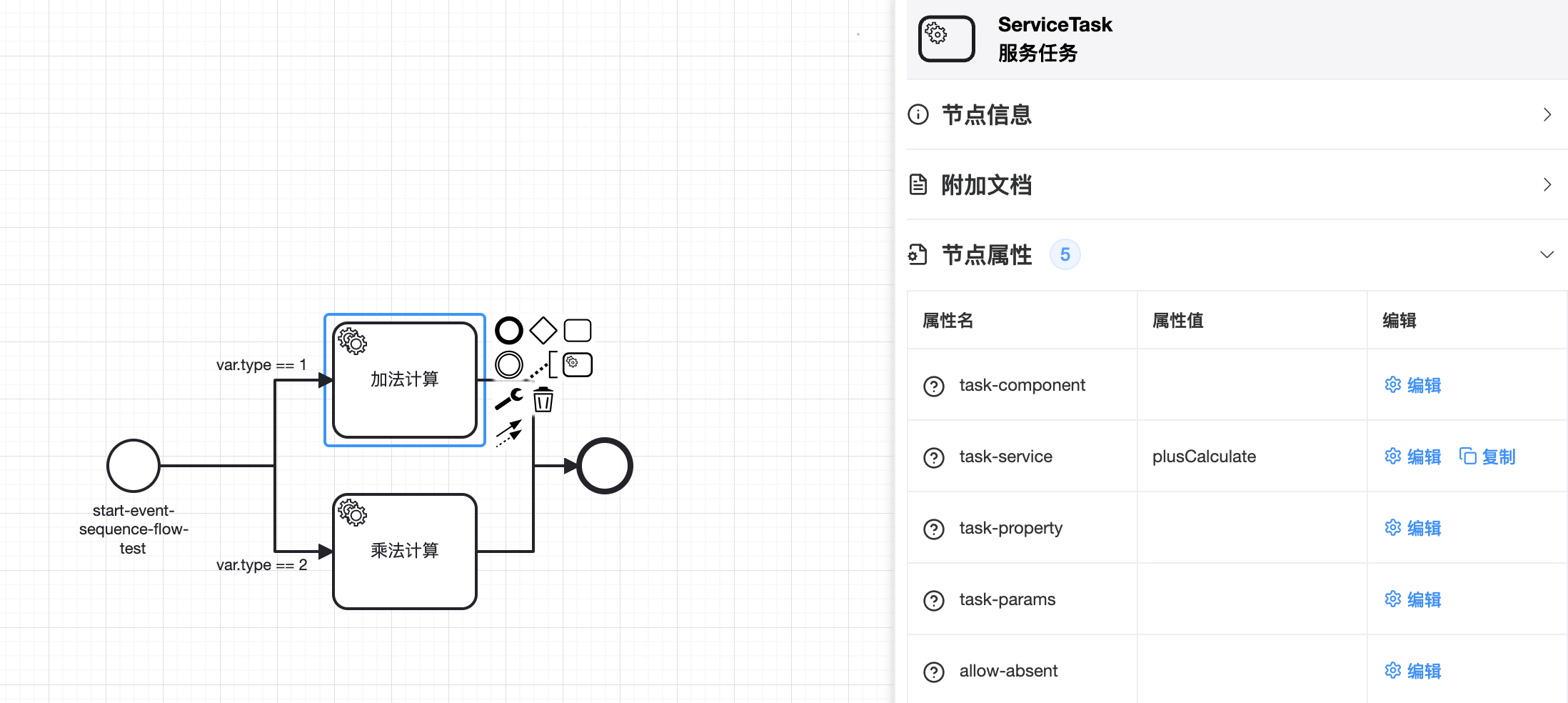
代码方式定义上述流程:
@Bean public ProcessLink startEventSequenceFlowProcess() { StartProcessLink processLink = StartProcessLink.build(ProcessConfig::startEventSequenceFlowProcess); processLink.nextService("var.type == 1", CalculateService::plusCalculate).build().end(); processLink.nextService("var.type == 2", CalculateService::multiplyCalculate).build().end(); return processLink; }1
2
3
4
5
6
7
定义服务组件并测试:
@TaskComponent
public class CalculateService {
@NoticeResult
@TaskService
public int plusCalculate(@VarTaskParam int a, @VarTaskParam int b) {
return a + b;
}
@NoticeResult
@TaskService
public int multiplyCalculate(@VarTaskParam int a, @VarTaskParam int b) {
return a * b;
}
}
/**
* type = 1 时执行加法
*/
@Test
public void testPlusCalculateByType1() {
InScopeData varScopeData = new InScopeData(ScopeTypeEnum.VARIABLE);
varScopeData.put(CommonFields.F.type, 1);
varScopeData.put(CommonFields.F.a, 11);
varScopeData.put(CommonFields.F.b, 6);
StoryRequest<Integer> fireRequest = ReqBuilder.returnType(Integer.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).varScopeData(varScopeData).startId("start-event-sequence-flow-test").build();
TaskResponse<Integer> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals(17, (int) result.getResult());
}
/**
* type = 2 时执行乘法
*/
@Test
public void testMultiplyCalculateByType2() {
InScopeData varScopeData = new InScopeData(ScopeTypeEnum.VARIABLE);
varScopeData.put(CommonFields.F.type, 2);
varScopeData.put(CommonFields.F.a, 11);
varScopeData.put(CommonFields.F.b, 6);
StoryRequest<Integer> fireRequest = ReqBuilder.returnType(Integer.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).varScopeData(varScopeData).startId("start-event-sequence-flow-test").build();
TaskResponse<Integer> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals(66, (int) result.getResult());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
🟢 如上所示定义了CalculateService服务组件,里面分别包含一个加法和乘法运算。两服务节点前的连线分别定义了var.type == 1和var.type == 2两个表达式,当type被分别指定1、2时,程序会执行对应的加法或乘法运算
🟢 Kstry 引擎中条件表达式解析器有三个,boolean解析器、角色鉴权解析器、Spel表达式解析器
🔷 如果是直接输入boolean值,比如 true、y、no等会被认定为 boolean 值,使用 boolean 解析器解析判断
🔷 如果符合权限定义的格式,使用角色鉴权解析器解析判断,后面讲到角色权限时会再详细介绍
🔷 前两者都不符合时则使用Spel表达式解析器,解析引擎是 Spring 的 Spel 解析器,表达式格式解析失败时会报错。解析结果一定得是Boolean值
🟢 事件(Event)、服务节点(ServiceTask)、网关(Gateway)都可以从当前节点引出多个支路(也叫允许有多个出度),1.1.12版本之前只有并行网关、包含网关、结束事件可以接收多个入度,其他节点有多个入度时会出现配置文件解析失败的报错,1.1.13及之后的版本去掉了该限制
🟢 服务节点(ServiceTask)、事件(Event)后面的出度如果没有定义表达式时,默认为true。不同类型的网关(Gateway)特点不同,后面会详细介绍
# 2.1.2 条件表达式函数
在流程定义中,如果遇到了比较复杂的条件表达式,仅仅使用普通条件表达式无法满足诉求时,就需要考虑使用条件表达式函数了。假设需要将上述例子中的var.type == 1改成使用Java中的Objects.equals()函数来进行判断,可以按以下方式来定义:
@Component
public class CustomExpressionFunction implements ExpressionAliasRegister {
@Override
public List<ExpressionAlias> registerAlias() {
return Lists.newArrayList(new ExpressionAlias("eq", Objects.class, "equals"));
}
}
2
3
4
5
6
7
8
上述定义完成之后,var.type == 1表达式就可以改成@eq(var.type, 1)了。表达式函数使用格式是:@{函数别名}({方法入参...})
🟢 任意定义一个类实现ExpressionAliasRegister接口,并将该类放到Spring容器中
🟢 实现ExpressionAliasRegister接口后需要实现registerAlias()方法,该方法返回一个ExpressionAlias对象的集合
🟢 ExpressionAlias对象构造函数有三个入参,含义依次是:使用函数时的别名、使用代码中的哪个类、使用类中的哪个静态方法的方法名 (需要注意一定得是类中静态的Public方法)
🟢 表达式函数支持并列和嵌套,类似这种@eq(@toInt(@toString(var.type)), @toInt('1')) && @noneNull(var.type)抽风的表达式也是可以正常执行的
🟢 可以定义与业务强相关的表达式函数来进行路由判断。当然表达式函数的功能之强大并不仅仅局限在条件判断上,甚至可以通过自定义函数接收数据域中的对象来进行操作。 比如类型转换、加工对象中的某些字段等
为了方便使用,框架提供了一些默认的表达式函数,在需要这些函数时无需额外定义就可以直接使用了。默认表达式函数的定义也同样使用了上述的方式,可以参考源码中的BasicExpressionAliasRegister来了解具体支持了哪些默认函数。
public class BasicExpressionAliasRegister implements ExpressionAliasRegister {
@Override
public List<ExpressionAlias> registerAlias() {
return Lists.newArrayList(
// object util
new ExpressionAlias(Exp.equals, Objects.class, "equals"),
new ExpressionAlias(Exp.notEquals, ExpressionAliasUtil.class, "notEquals"),
new ExpressionAlias(Exp.isNull, Objects.class, "isNull"),
new ExpressionAlias(Exp.notNull, Objects.class, "nonNull"),
new ExpressionAlias(Exp.anyNull, ExpressionAliasUtil.class, "anyNull"),
new ExpressionAlias(Exp.noneNull, ObjectUtils.class, "allNotNull"),
// string util
new ExpressionAlias(Exp.isBlank, StringUtils.class, "isBlank"),
new ExpressionAlias(Exp.notBlank, StringUtils.class, "isNotBlank"),
new ExpressionAlias(Exp.noneBlank, StringUtils.class, "isNoneBlank"),
new ExpressionAlias(Exp.allBlank, StringUtils.class, "isAllBlank"),
new ExpressionAlias(Exp.anyBlank, StringUtils.class, "isAnyBlank"),
new ExpressionAlias(Exp.toString, ExpressionAliasUtil.class, "toString"),
// number util
new ExpressionAlias(Exp.isNumber, NumberUtils.class, "isCreatable"),
new ExpressionAlias(Exp.toInt, NumberUtils.class, "toInt"),
new ExpressionAlias(Exp.toLong, NumberUtils.class, "toLong"),
new ExpressionAlias(Exp.toDouble, NumberUtils.class, "toDouble"),
new ExpressionAlias(Exp.toFloat, NumberUtils.class, "toFloat"),
new ExpressionAlias(Exp.toByte, NumberUtils.class, "toByte"),
new ExpressionAlias(Exp.toShort, NumberUtils.class, "toShort"),
// bool util
new ExpressionAlias(Exp.toBool, BooleanUtils.class, "toBoolean"),
new ExpressionAlias(Exp.isTrue, BooleanUtils.class, "isTrue"),
new ExpressionAlias(Exp.isFalse, BooleanUtils.class, "isFalse"),
new ExpressionAlias(Exp.notFalse, BooleanUtils.class, "isNotFalse"),
new ExpressionAlias(Exp.notTrue, BooleanUtils.class, "isNotTrue"),
// common util
new ExpressionAlias(Exp.max, ObjectUtils.class, "max"),
new ExpressionAlias(Exp.min, ObjectUtils.class, "min"),
new ExpressionAlias(Exp.isEmpty, ExpressionAliasUtil.class, "isEmpty"),
new ExpressionAlias(Exp.notEmpty, ExpressionAliasUtil.class, "notEmpty"),
new ExpressionAlias(Exp.contains, ExpressionAliasUtil.class, "contains"),
new ExpressionAlias(Exp.size, ExpressionAliasUtil.class, "size"),
new ExpressionAlias(Exp.validId, ExpressionAliasUtil.class, "validId")
);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
当通过代码方式定义流程时,框架还提供了Exp类来辅助定义条件表达式,比如上面的流程就可以写成下面这种
@Bean
public ProcessLink startEventSequenceFlowProcess() {
StartProcessLink processLink = StartProcessLink.build(ProcessConfig::startEventSequenceFlowProcess);
processLink.nextService(Exp.b(e -> e.equals("var.type", "1")), CalculateService::plusCalculate).build().end();
processLink.nextService(Exp.b(e -> e.equals("var.type", "2")), CalculateService::multiplyCalculate).build().end();
return processLink;
}
2
3
4
5
6
7
自定义函数时,还可以自定义工具类继承Exp来扩展支持
/**
* 扩展工具类
*/
public class Ex extends Exp<Ex> {
public Ex customEquals(String left, String right) {
this.expression = GlobalUtil.format("{}@eq({}, {})", this.expression, left, right);
return this;
}
public static String bu(Consumer<Ex> builder) {
return b(new Ex(), builder);
}
}
@Bean
public ProcessLink startEventSequenceFlowProcess() {
StartProcessLink processLink = StartProcessLink.build(ProcessConfig::startEventSequenceFlowProcess);
processLink.nextService(Ex.bu(e -> e.customEquals("var.type", "1")), CalculateService::plusCalculate).build().end();
processLink.nextService(Ex.bu(e -> e.customEquals("var.type", "2")), CalculateService::multiplyCalculate).build().end();
return processLink;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 2.1.3 条件表达式执行顺序
支持o{数字}: 表达式(比如:o1: var.type == 1 ),来定义各个支路上表达式的执行顺序,数字越小优先级越高。未指定顺序时表达式默认为最低优先级
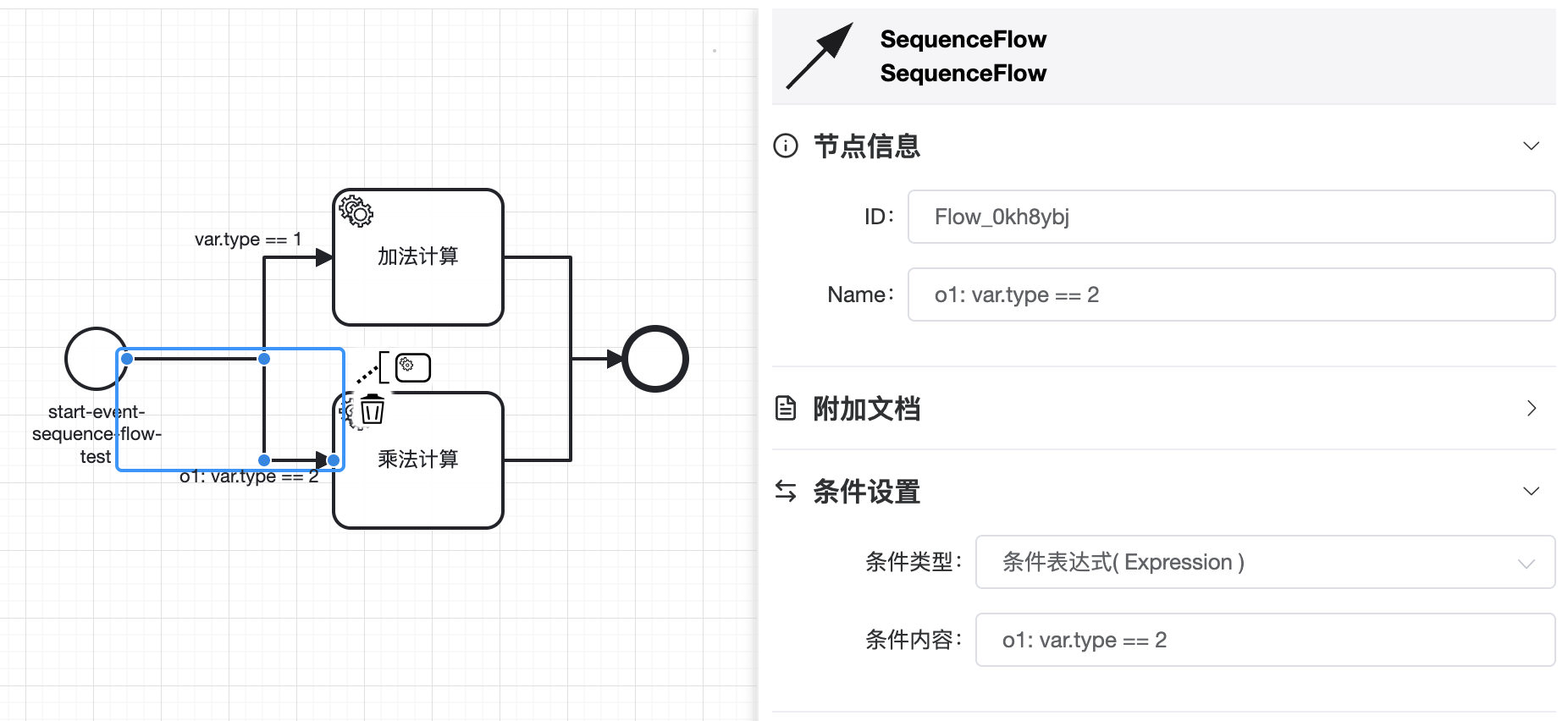
上图由于指定了流程表达式优先级为1,所以乘法计算服务节点前的表达式会先被执行,之后才会是加法计算服务节前的表达式。
再一个场景排他网关出度连线上的表达式,只要有一个执行结果为true,其他出度后面的流程都不会再执行了,同样的与他们相关的条件表达式也不会再执行。此时就可能需要指定哪个条件先判断。节点多个出度表达式分别设置执行顺序就相当于是代码中的if... else if... else if... else
# 2.2 并行网关
TIP
程序中经常会遇到一些通过并发调用各类接口来加载各类资源信息的例子,通过并发操作可以获取更短的响应时长。在Kstry框架中只要后一个节点的入参和前一个节点的出参没有前后依赖关系就可以通过并行网关配置并行
BPMN图示如下:
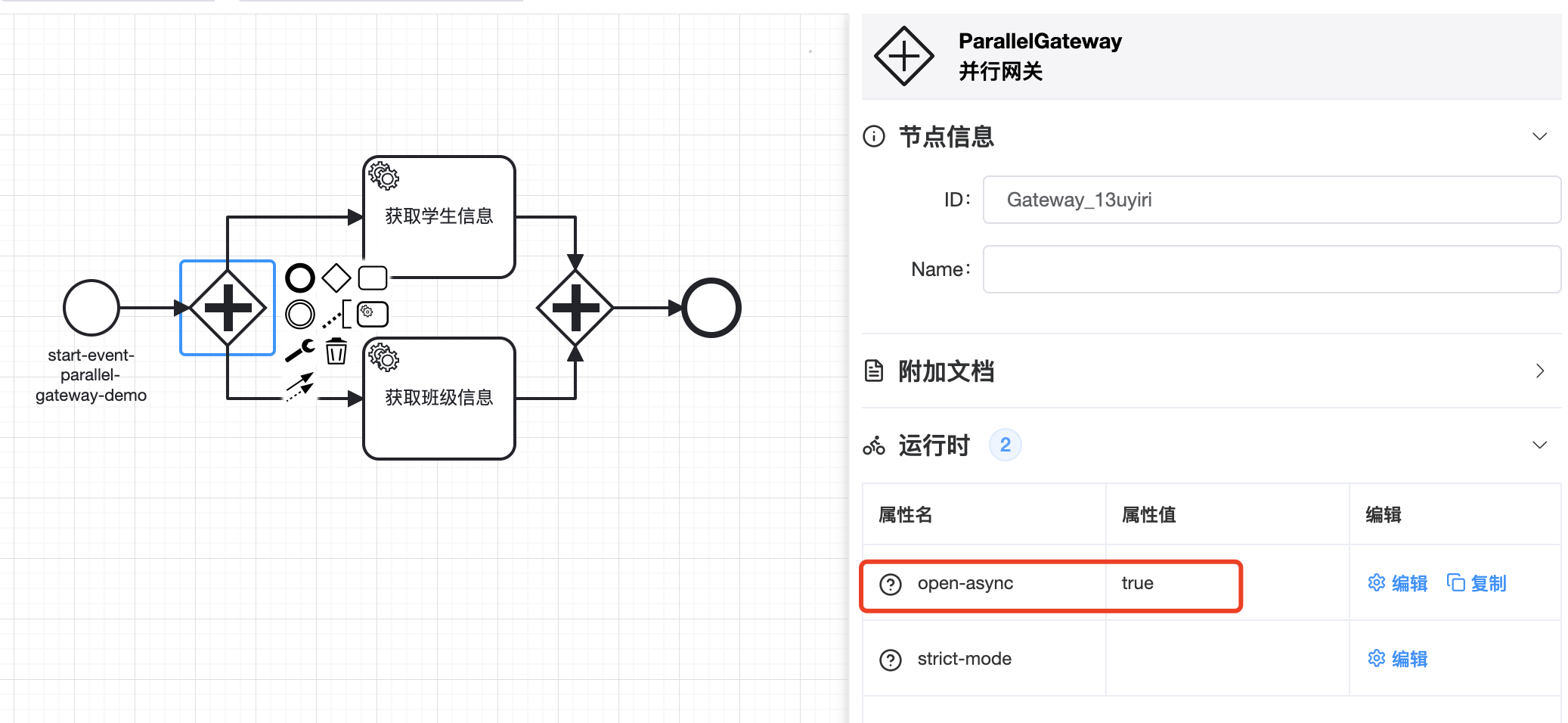
代码方式定义上述流程:
@Bean public ProcessLink testParallelGatewayDemoProcess() { StartProcessLink processLink = StartProcessLink.build(ProcessConfig::testParallelGatewayDemoProcess); ParallelJoinPoint parallelJoinPoint = processLink.nextParallel(processLink.parallel().openAsync().build()); processLink.parallel().build().joinLinks( parallelJoinPoint.nextService(FlowDemoService::getStudentInfo).build(), parallelJoinPoint.nextService(FlowDemoService::getClassInfo).build() ).end(); return processLink; }1
2
3
4
5
6
7
8
9
10
定义服务组件:
@NoticeVar
@TaskService(desc = "获取学生信息")
public Student getStudentInfo(@VarTaskParam Long studentId) {
Student student = new Student();
student.setId(studentId);
student.setName("Name" + studentId);
return student;
}
@NoticeVar
@TaskService(desc = "获取班级信息")
public ClassInfo getClassInfo(@VarTaskParam Long classId) {
ClassInfo classInfo = new ClassInfo();
classInfo.setId(classId);
classInfo.setName("Name" + classId);
return classInfo;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
测试执行:
@Test
public void testParallelGatewayDemo() {
// var 域初始化数据
InScopeData varScopeData = new InScopeData(ScopeTypeEnum.VARIABLE);
varScopeData.put(CommonFields.F.studentId, 11);
varScopeData.put(CommonFields.F.classId, 66);
// 构造request
StoryRequest<Map<String, Object>> fireRequest = ReqBuilder.<Map<String, Object>>resultType(Map.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).varScopeData(varScopeData).startId("start-event-parallel-gateway-demo")
.resultBuilder((Object r, ScopeDataQuery query) -> { // r: 流程执行完返回的结果(如果有)
HashMap<String, Object> objMap = Maps.newHashMap();
objMap.put(CommonFields.F.student, query.getVarData(CommonFields.F.student));
objMap.put(CommonFields.F.classInfo, query.getVarData(CommonFields.F.classInfo));
return objMap;
}).build();
// 执行
TaskResponse<Map<String, Object>> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertNotNull(result.getResult().get(CommonFields.F.student));
Assert.assertNotNull(result.getResult().get(CommonFields.F.classInfo));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
🟢 使用并行网关时,一般会有前后两个并行网关节点一起出现,前面将一个分支拆解成多个,后面将多个分支进行聚合
🟢 并行网关支持开启异步流程。未开启异步流程时,并行网关拆分出的多个分支还是一个线程逐一执行,开启异步流程后,每个分支都会被构建成异步任务提交到线程池中执行
🟢 当并行网关后要执行的分支数量为1时,开启并发的操作无效,还会是当前线程同步执行后面一个分支的任务
🟢 并行网关后面的出度如果有表达式,表达式会被忽略,无论设置与否都不会解析,都会默认为true
🟢 并行网关要求所有入度全部执行完才能向下继续,否则将一直等待。如果并行网关入度中由于表达式执行结果为false等原因导致不可达时会有类似报错:
[K1040008] A process branch that cannot reach the ParallelGateway appears! sequence flow: SEQUENCE_FLOW:[id: c9c35988942e4ac79bab9a5689522887-7, name: ], parallel gateway: PARALLEL_GATEWAY:[id: 154a637311c646b1ad54e969eaa52b41-10, name: null]
🟢 解决这个问题有两种方式:
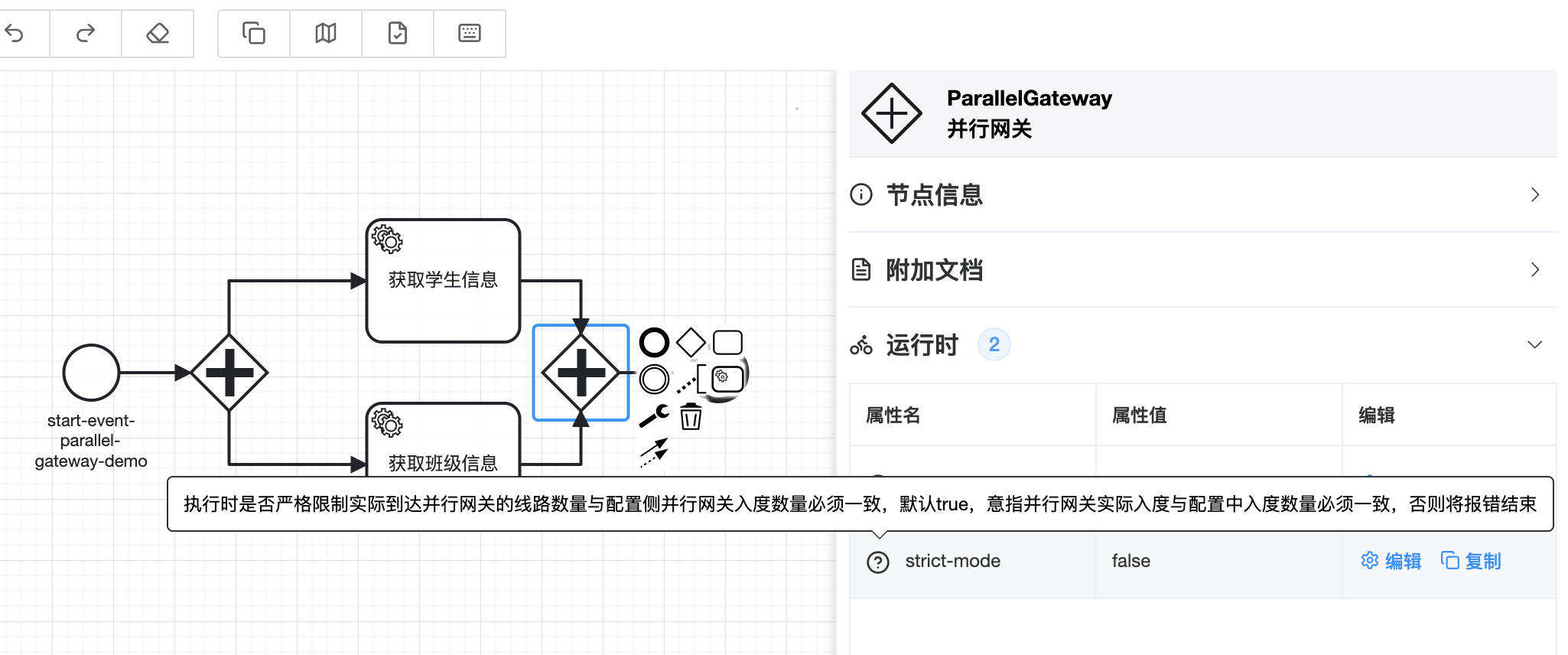
🔷 将并行网关改为包含网关,包含网关不要求所有入度分支都必须被执行,并且还拥有并行网关开启并发、汇聚并行分支等特性
🔷 如下图,关闭并行网关的严格模式:strict-mode=false。关闭严格模式的并行网关,不再限制网关入度必须都被执行。关闭严格模式的并行网关与包含网关也并非是完全等价的。因为并行网关后面出度的条件表达式是被忽略的,但是包含网关后面出度的条件表达式是会被解析执行起到决策作用的
# 2.3 排他网关
TIP
程序中经常会使用if... else if... else if... else...的逻辑。Kstry框架中可以使用排他网关实现完全相同的逻辑。“排他”顾名思义,网关后面最终只有一个分支被执行,其他分支都会被中断
BPMN图示如下:
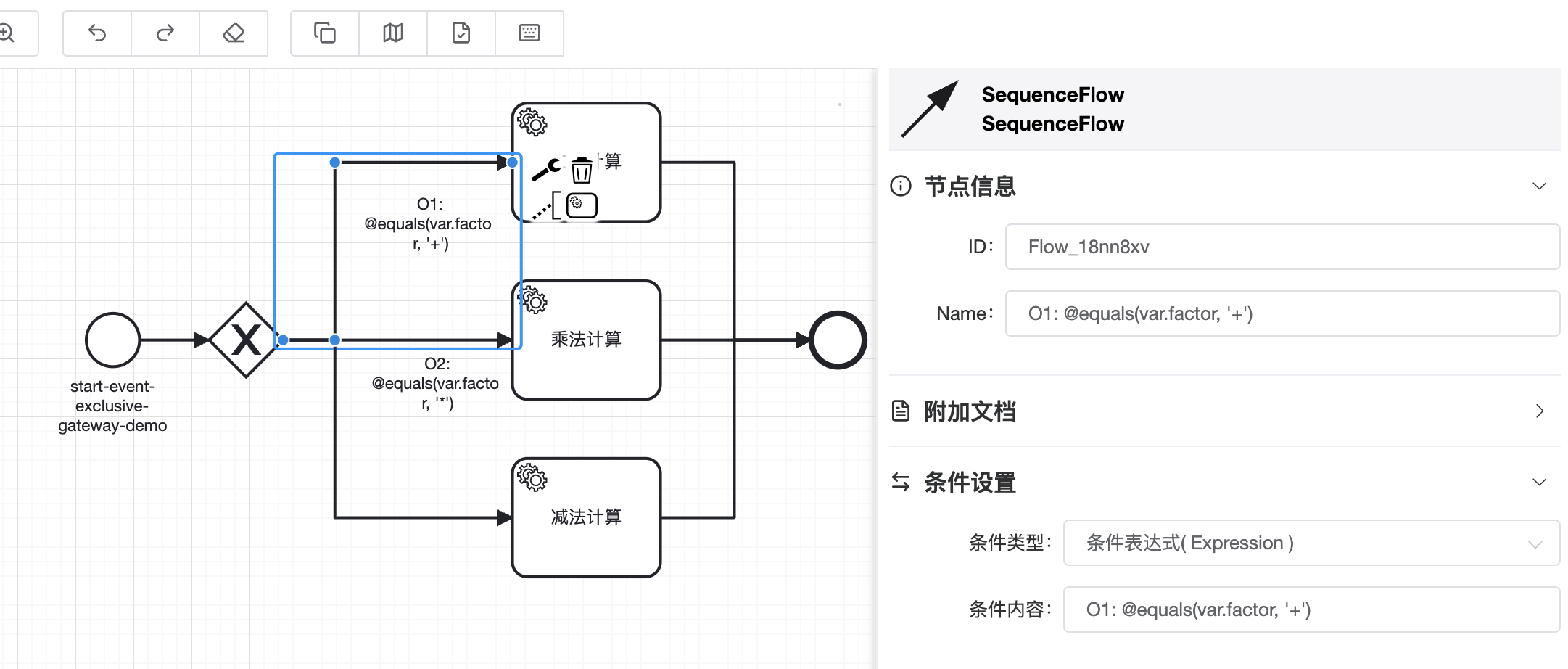
介绍顺序流连线时有提及,框架支持o{数字}: 表达式(比如:
O1: @equals(var.factor, '+')),来定义各个支路上表达式的执行顺序,数字越小优先级越高。未指定顺序时表达式默认为最低优先级
代码方式定义上述流程:
@Bean public ProcessLink testExclusiveGatewayDemoProcess() { StartProcessLink processLink = StartProcessLink.build(ProcessConfig::testExclusiveGatewayDemoProcess); ProcessLink exclusive = processLink.nextExclusive().build(); exclusive.nextService(Ex.b(e -> e.order(1).equals("var.factor", "'+'")), CalculateService::plusCalculate).build().end(); exclusive.nextService(Ex.b(e -> e.order(2).equals("var.factor", "'*'")), CalculateService::multiplyCalculate).build().end(); exclusive.nextService(CalculateService::minusCalculate).build().end(); return processLink; }1
2
3
4
5
6
7
8
9
定义服务组件:
@NoticeResult
@TaskService
public int plusCalculate(@VarTaskParam int a, @VarTaskParam int b) {
return a + b;
}
@NoticeResult
@TaskService
public int multiplyCalculate(@VarTaskParam int a, @VarTaskParam int b) {
return a * b;
}
@NoticeResult
@TaskService
public int minusCalculate(@VarTaskParam int a, @VarTaskParam int b) {
return a - b;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
测试执行:
@Test
public void testExclusiveGatewayDemo() {
// var 域初始化数据
InScopeData varScopeData = new InScopeData(ScopeTypeEnum.VARIABLE);
varScopeData.put(CommonFields.F.a, 11);
varScopeData.put(CommonFields.F.b, 6);
// 构造request
StoryRequest<Integer> fireRequest = ReqBuilder.returnType(Integer.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).varScopeData(varScopeData).startId("start-event-exclusive-gateway-demo")
.build();
// 执行 默认
TaskResponse<Integer> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 5);
// 执行 +
varScopeData.put(CommonFields.F.factor, "+");
result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 17);
// 执行 *
varScopeData.put(CommonFields.F.factor, "*");
result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 66);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
🟢 1.1.12版本之前只有并行网关、包含网关、结束事件可以接收归并多个入度,显然排他网关并不在此列,也就是说排他网关只能接收一个入度,不允许多个箭头指向同一个排他网关。1.1.13及之后的版本去掉了该限制
🟢 排他网关入度只能有一个,出度可以多个。出度上面的条件表达式会被解析执行,如果没有条件表达式时会默认是true
🟢 排他网关有多个出度表达式被解析成true时,会选择第一个为true的分支继续向下执行,其他的将会被忽略。图示中出度的前后并不代表程序解析时出度上表达式判断执行的先后顺序,需要指定顺序时可以使用o{数字}: 表达式
🟢 当全部出度上的表达式都解析为false时会抛出异常并结束流程,异常信息`:
[K1040008] Match to the next process node as empty! current node identity: EXCLUSIVE_GATEWAY:[id: eeec292f8c5e47919238eb9acd031ce5-3, name: null], desired list of possible nodes for later execution: SERVICE_TASK:[id: 1a5bda10f58a41f1a0c80bbcdcfc9b59-5, name: null, component: calculateService, service: plusCalculate], SERVICE_TASK:[id: bb2806a1ec3f4464a3333cde5c7feabf-8, name: null, component: calculateService, service: multiplyCalculate], SERVICE_TASK:[id: c108dc8d31bf4a71bebf97fedf66432e-11, name: null, component: calculateService, service: minusCalculate]
🟢 由于排他网关最终执行的只有一条链路,所以排他网关是不支持开启异步的,因为没啥意义
# 2.4 包含网关
TIP
包含网关是并行网关和排他网关的结合。包含网关可以像排他网关一样执行后面出度上的表达式,还不像排他网关一样有最多执行一个分支的限制。包含网关可以像并行网关一样聚合分支、开启后续分支的并发,还不会像并行网关一样要求全部入度都必须被执行
BPMN图示如下:
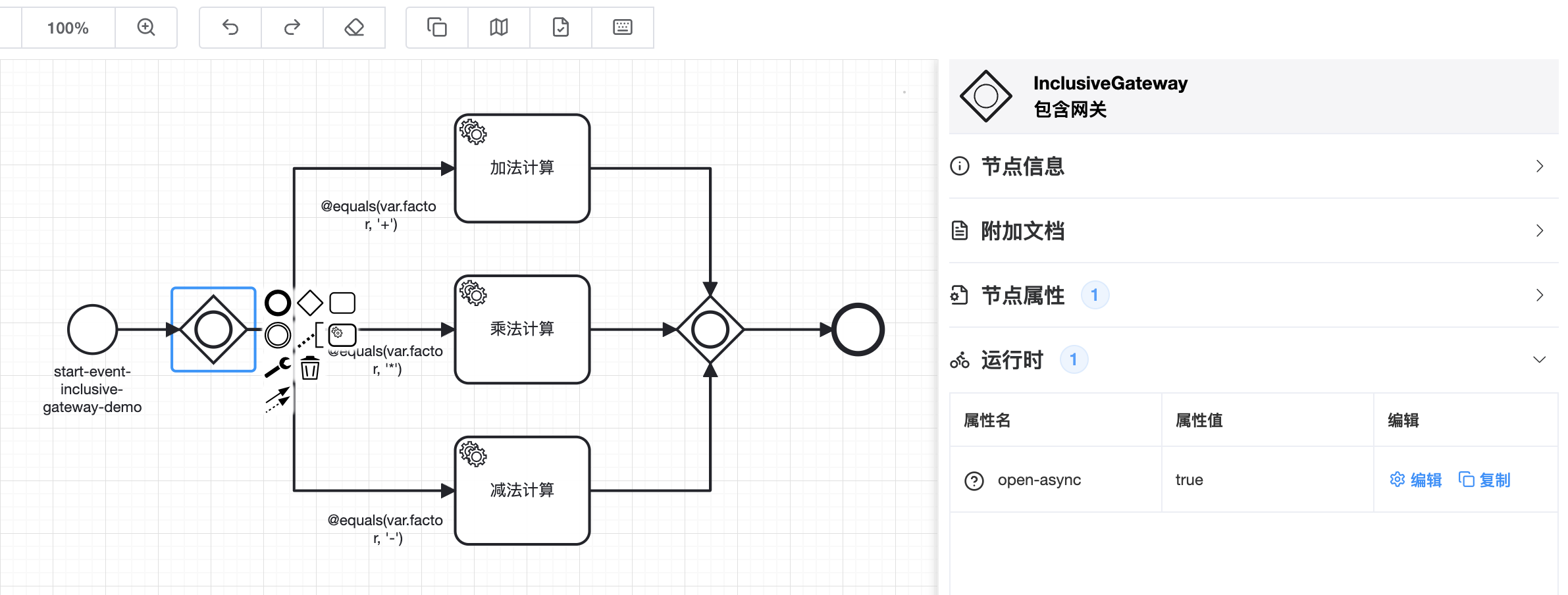
代码方式定义上述流程:
@Bean public ProcessLink testInclusiveGatewayDemoProcess() { StartProcessLink processLink = StartProcessLink.build(ProcessConfig::testInclusiveGatewayDemoProcess); InclusiveJoinPoint inclusiveJoinPoint = processLink.nextInclusive(processLink.inclusive().openAsync().build()); processLink.inclusive().build().joinLinks( inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'+'")), CalculateService::plusCalculate).build(), inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'*'")), CalculateService::multiplyCalculate).build(), inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'-'")), CalculateService::minusCalculate).build() ).end(); return processLink; }1
2
3
4
5
6
7
8
9
10
11
12
测试执行:
@Test
public void testInclusiveGatewayDemo() {
// var 域初始化数据
InScopeData varScopeData = new InScopeData(ScopeTypeEnum.VARIABLE);
varScopeData.put(CommonFields.F.a, 11);
varScopeData.put(CommonFields.F.b, 6);
// 构造request
StoryRequest<Integer> fireRequest = ReqBuilder.returnType(Integer.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).varScopeData(varScopeData).startId("start-event-inclusive-gateway-demo")
.build();
// 执行 -
varScopeData.put(CommonFields.F.factor, "-");
TaskResponse<Integer> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 5);
// 执行 +
varScopeData.put(CommonFields.F.factor, "+");
result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 17);
// 执行 *
varScopeData.put(CommonFields.F.factor, "*");
result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 66);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
🟢 包含网关与并行网关一样,支持开启异步流程,支持接收多个入度
🟢 包含网关没有所有入度必须被执行的限制,等待全部入度执行完成或者得知其中可能有部分入度不满足条件不再执行后,会继续向下执行
🟢 包含网关后面出度可以设置条件表达式,表达式解析规则与排他网关出度解析规则相同,但没有最多执行一个分支的限制,只要出度上的表达式解析为true都会被执行
🟢 如果需要指定包含网关前面入度任务完成几个便可继续向下执行时,可以使用completed-count属性
🔷 completed-count设置时要求必须小于等于包含网关入度数量,否则启动时报错:[K1030005] completed-count cannot be greater than comingList size!
🔷 假设一个包含网关入度是3,completed-count指定2,执行时当网关前面有两个入度完成时便可以继续向下执行。如果最终只有1个入度能完成则会抛出[K1040008] The actual completed flow does not meet the requirements of completedCount!异常结束流程
🔷 未指定completed-count属性时,默认是等待全部入度反馈到达或不能到达信号才会继续流程,如果最终没有一个入度到达网关流程也会被异常终止
🟢 包含网关支持定义midway-start-id属性来指定中途开始节点ID,结合request中传入的midwayStartId属性值可以使流程从中间节点开始执行
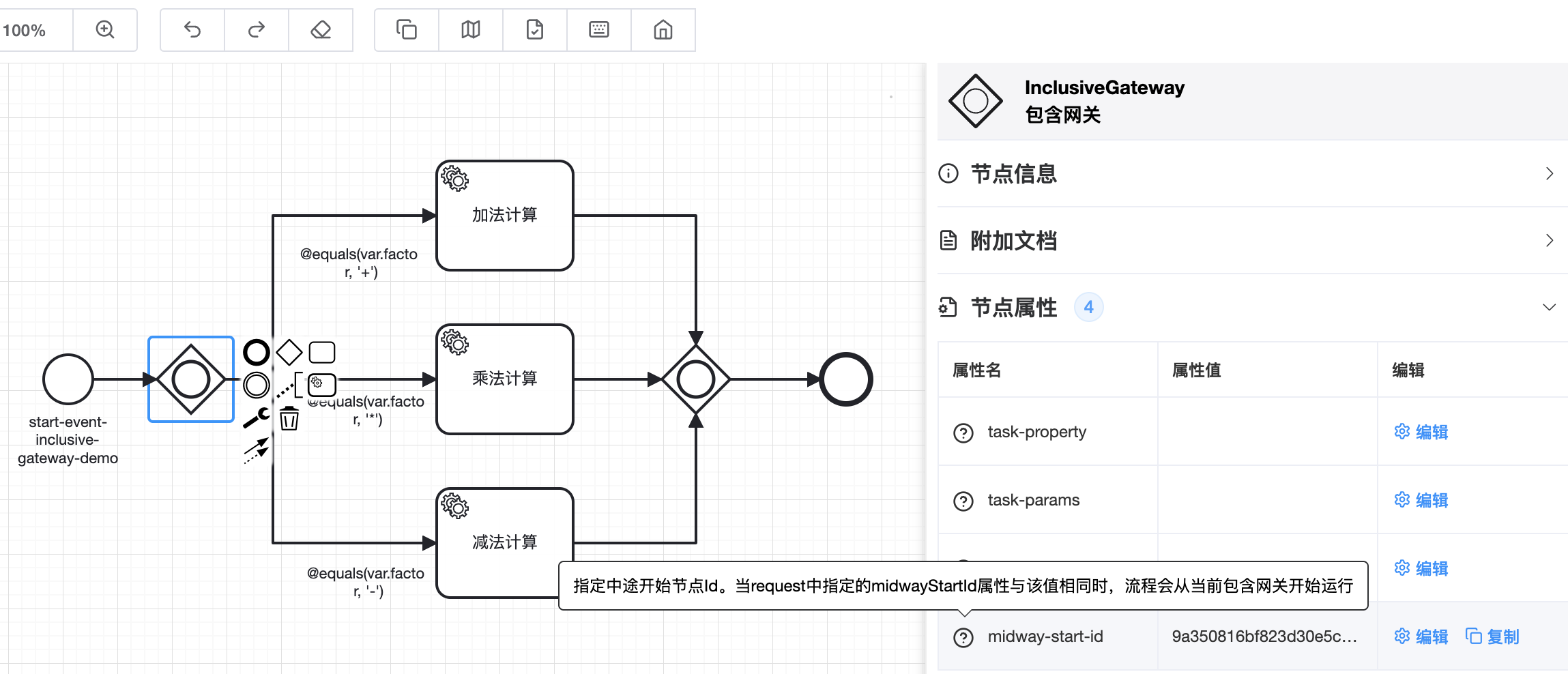
调用时时指定midwayStartId属性,让上述流程从包含网关开始执行
@Test
public void testInclusiveMidwayStart() {
// var 域初始化数据
InScopeData varScopeData = new InScopeData(ScopeTypeEnum.VARIABLE);
varScopeData.put(CommonFields.F.a, 11);
varScopeData.put(CommonFields.F.b, 6);
// 构造request
StoryRequest<Integer> fireRequest = ReqBuilder.returnType(Integer.class).midwayStartId("9a350816bf823d30e5ca2865dd3a147f")
.trackingType(TrackingTypeEnum.ALL).varScopeData(varScopeData).startId("start-event-inclusive-gateway-demo")
.build();
// 执行 -
varScopeData.put(CommonFields.F.factor, "-");
TaskResponse<Integer> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 5);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
🔷 子流程中的包含网关不能定义midway-start-id属性,即只有主流程中才能从中间节点开始执行
🔷 如果request中指定了midwayStartId但在实际执行时却没有找到对应节点会报错,未指定midwayStartId时默认从startEvent开始执行
🔷 一定需要注意!!!指定midwayStartId属性从流程中间开始执行的包含网关后面出现的所有包含网关、并行网关、排他网关前面的入度要保证经过此包含网关都是可达的,不然会出现因为等待永不可达流程导致调用超时的问题!!!
🔷 下图所示的流程中出现的包含网关就不能配置midway-start-id。因为从包含网关开始后,结束节点下方的入度是永不可达的,会出现等待超时异常
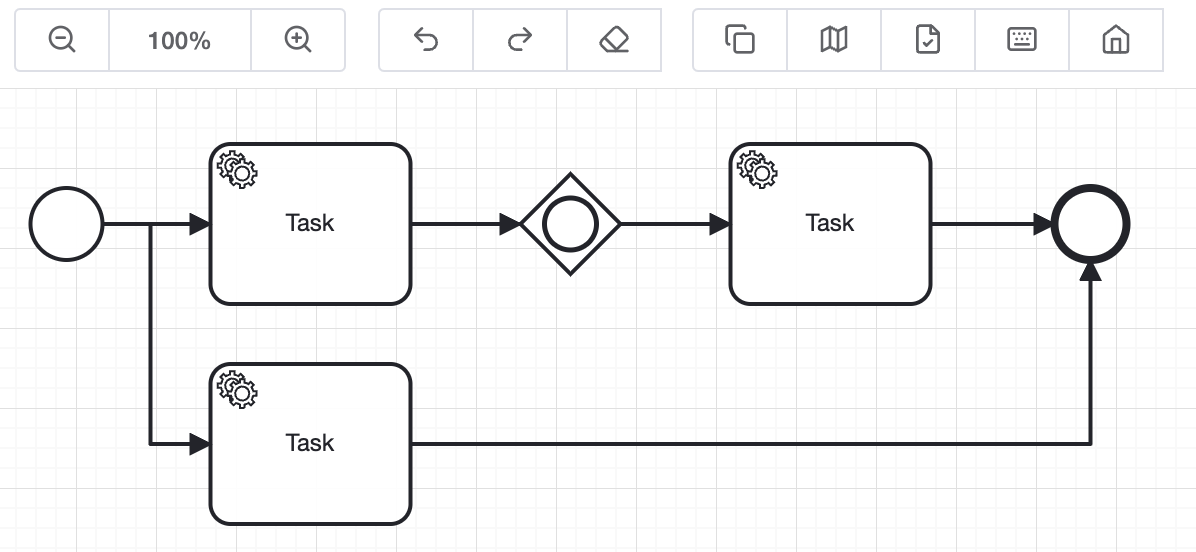
# 2.5 子流程
# 2.5.1 子流程使用
TIP
框架支持定义子流程。可以用来进行复杂流程的拆分、通用流程的复用、流程事务管理等。子流程可以做到逻辑的抽离,以便之后进行单独维护升级。这样也使原来比较复杂的流程图得到了简化,理解起来会更加方便
BPMN图示如下:
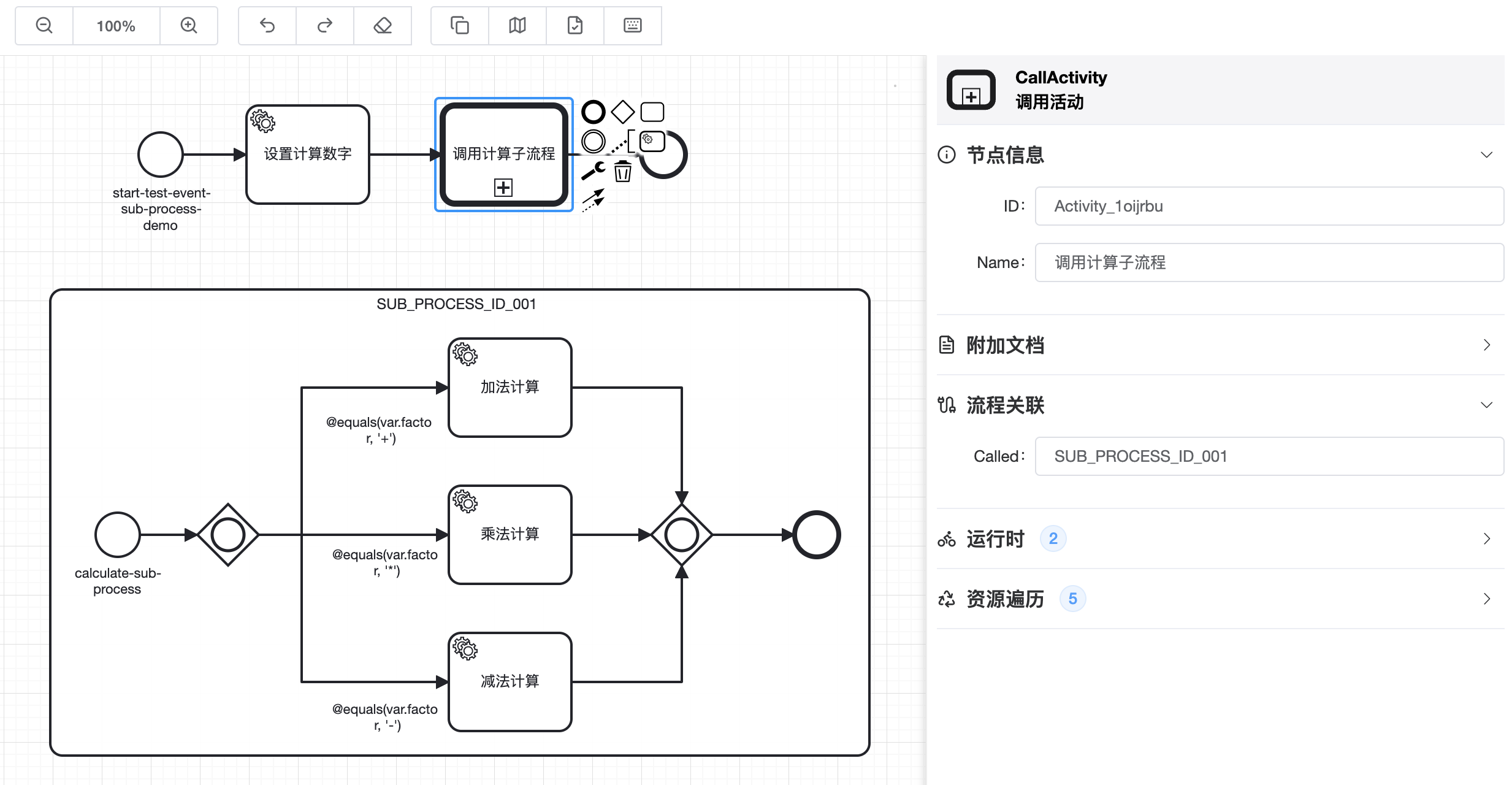
注意!图中SUB_PROCESS_ID_001关联ID,是子流程的ID,不是子流程中开始事件的ID
代码方式定义上述流程:
/** * 定义子流程 */ @Bean public SubProcessLink calculateSubProcessDemo() { return SubProcessLink.build(ProcessConfig::calculateSubProcessDemo, link -> { InclusiveJoinPoint inclusiveJoinPoint = link.nextInclusive(link.inclusive().openAsync().build()); link.inclusive().build().joinLinks( inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'+'")), CalculateService::plusCalculate).build(), inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'*'")), CalculateService::multiplyCalculate).build(), inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'-'")), CalculateService::minusCalculate).build() ).end(); }); } @Bean public ProcessLink testCalculateSubProcessDemo() { StartProcessLink processLink = StartProcessLink.build(ProcessConfig::testCalculateSubProcessDemo); processLink .nextService(CalculateService::setCalculateNumber).params("{'a': 11, 'b': 6}").build() .nextSubProcess(ProcessConfig::calculateSubProcessDemo).build() // 引用子流程 .end(); return processLink; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
测试执行:
@Test
public void testSubProcessDemo() {
// 执行 *
InScopeData varScopeData = new InScopeData(ScopeTypeEnum.VARIABLE);
varScopeData.put(CommonFields.F.factor, "*");
// 构造request
StoryRequest<Integer> fireRequest = ReqBuilder.returnType(Integer.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).varScopeData(varScopeData).startId("start-test-event-sub-process-demo")
.build();
TaskResponse<Integer> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 66);
// 代码方式定义流程
varScopeData.put(CommonFields.F.factor, "+");
fireRequest = ReqBuilder.returnType(Integer.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).varScopeData(varScopeData).startProcess(ProcessConfig::testCalculateSubProcessDemo)
.build();
result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 17);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
🟢 子流程有独立于父流程之外的开始事件、结束事件
🟢 子流程是支持嵌套的,A子流程可以依赖B子流程,但是自身依赖自身是非法的
🟢 子流程中的包含网关、并行网关也支持开启异步模式
🟢 BPMN文件中定义bpmn:callActivity引用子流程,代码定义中使用.nextSubProcess(Xxx).build()引用子流程。程序运行到此时会跳转至子流程执行,子流程执行完成后才会跳转回主流程继续执行
# 2.5.2 子流程拦截器
TIP
业务动作复用、复杂业务动作抽离并单独维护、第三方提供的一些服务能力等,都需要定义子流程来进行业务间隔离。被划分出来的子流程可以被看作一个整体被单独维护。框架提供了定义子流程拦截器的能力,可以在子流程执行前、执行后、出现异常(链路中出现异常或者超时)时自定义操作。除此之外,还可以定义无论是否出现异常都一定会执行的最终通知
@Component
public class StatisticsInterceptor implements SubProcessInterceptor {
/**
* 子流程拦截器的切入点
*/
@Override
public Set<String> pointcut() {
return Sets.newHashSet("Event_1h3q9xl", "Event_08xh60r"); // 这里指定的是子流程中的开始事件ID
}
@Override
public boolean beforeProcessor(ScopeDataOperator dataOperator, Role role) {
// 开始统计
log.info("开始统计...");
return true;
}
@Override
public void afterProcessor(ScopeDataOperator dataOperator, Role role) {
// 统计结束
log.info("统计结束...");
}
@Override
public void errorProcessor(Throwable exception, ScopeDataOperator dataOperator, Role role) {
// 统计异常
log.info("统计异常...");
}
@Override
public void finallyProcessor(ScopeDataOperator dataOperator, Role role) {
// 兜底逻辑
log.info("兜底逻辑...");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
🟢 定义实现SubProcessInterceptor接口的子流程拦截器,并交给Spring容器管理,拦截器即可生效
🟢 pointcut() 方法需要被实现,返回子流程中开始事件ID的Set集合,以此告知框架哪些子流程需要被拦截器处理
🟢 不同流程共同引用一个子流程时,拦截器如果要区分不同的主流程 pointcut() 方法就无法支持了。此时需要实现getSubProcessIdentity()方法,它返回一个SubProcessIdentity对象的Set集合。框架用SubProcessIdentity对象集合来判断当前拦截器是否生效。SubProcessIdentity有两种构造参数:
🔷 传入子流程的startEventId,运行过程中拦截器定义的startEventId与子流程的startEventId相同时当前拦截器生效
public SubProcessIdentity(String startEventId) {
this(startEventId, null);
}
2
3
🔷 传入子流程的startEventId和storyId(最外层流程中的startEventId),运行过程中startEventId和storyId都匹配成功时当前拦截器生效
public SubProcessIdentity(String startEventId, String storyId) {
super(TaskServiceUtil.joinName(startEventId, storyId), IdentityTypeEnum.SUB_PROCESS);
}
2
3
🟢 beforeProcessor是子流程的前置通知方法,拦截器匹配成功后,进入子流程之前被执行。用来实现一些子流程执行之前的业务动作。它返回一个boolean变量。true代表进入子流程,fasle代表跳过子流程继续执行下一节点
🟢 afterProcessor是子流程的后置通知,拦截器匹配成功,子流程执行完成之后会执行其中定义的业务动作
🟢 errorProcessor是子流程的异常通知,拦截器匹配成功后,子流程执行中出现异常或超时时会执行其中定义的业务动作
🟢 finallyProcessor是子流程的最终通知,拦截器匹配成功后,无论子流程是否执行成功,只要进入了子流程最终一定会执行其中定义的业务动作
🟢 getOrder()可以控制多个拦截器生效的前后顺序。与Spring中的Order相同,返回的变量值越小优先级越高。没有复写该方法时默认返回1000
# 2.5.3 子流程控制
TIP
并非所有子流程都是业务的核心逻辑,也并非所有子流程执行时间都与父流程相同。所以框架提供了给子流程设置严格模式和超时时间的入口
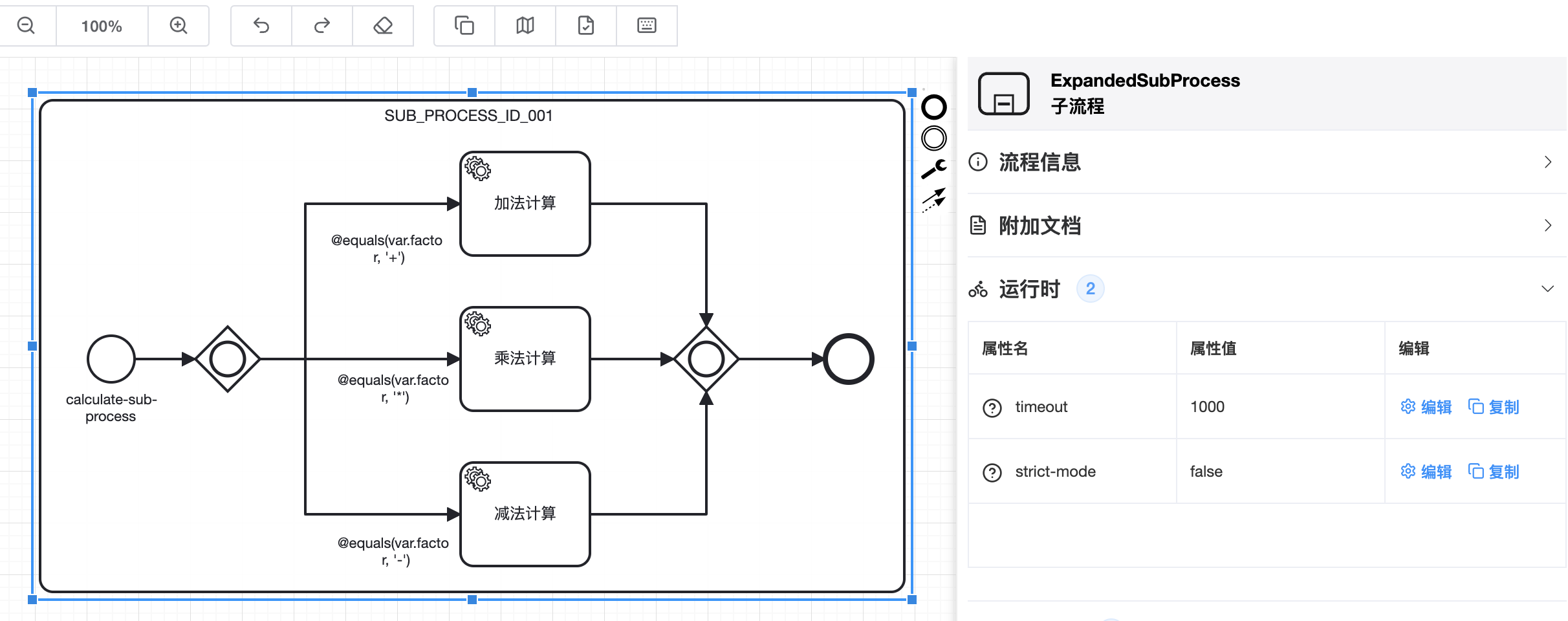
🟢 timeout以ms为单位。当timeout存在且大于等于0时,即可控制允许子流程执行的最大超时时间。达到最大超时时间之后,如果子流程还未结束就会抛出超时异常
🟢 strict-mode未被显示设置时默认为true,子流程出现异常或执行超时时会结束整个流程。strict-mode被设置成false后,如果子流程出现异常或执行超时,异常将会被忽略,当前子流程和所属当前子流程的子流程将会被中断。之后继续执行子流程后面的服务节点
🟢 not-skip-task用来控制子流程是否不执行直接跳过的条件表达式,表达式格式和连线上的条件表达式相同。默认为空,代表不跳过。该属性出现在1.1.15及之后的版本
# 2.6 回环流程
# 2.6.1 回环流程的使用
TIP
一般情况下流程配置的形式是有向无环图,但也不能避免会有一些特殊业务需要回环多次来执行当前流程。框架从1.1.15版本开始支持回环链路
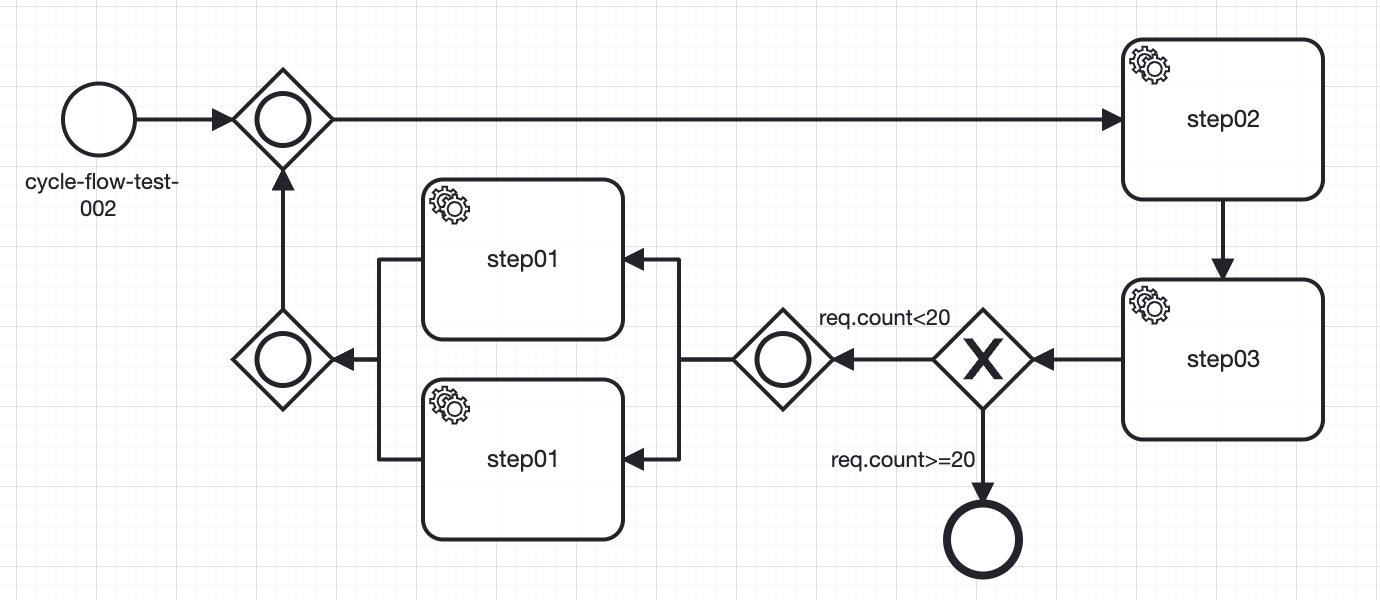
🟢 如图所示就是一个回环流程的配置,一个流程配置中只允许一个环路的出现,如果超过了,流程解析时就会报错
🟢 存在环路的流程里面有且仅有一个结束节点,且结束节点只允许有一个入度,该入度的前一个节点必须是排他网关
🟢 排他网关是判断回环线路是否结束的关键,它将被要求必须有两个出度,一个指向结束节点,一个指向后续的流程。两个出度上的条件表达式不允许相同
🟢 排他网关两侧的流程只有一个交点,也是环路流程的交点。除此之外,流程中将不允许出现其他环路交点的存在
🟢 在环路流程中,不建议与开启并发且设置了completed-count属性的包含网关一起使用,否则有可能出现未知情况
🟢 只要满足以上全部条件,环路流程就可以正常工作,且框架的其他功能也可以结合其中一起使用
# 2.6.2 支持多回环流程
TIP
从上面的描述来看,众多使用条件限制了一个流程中只能有一个回环,而且还不能配置其他非回环的业务流程,这个问题可以通过子流程来解决
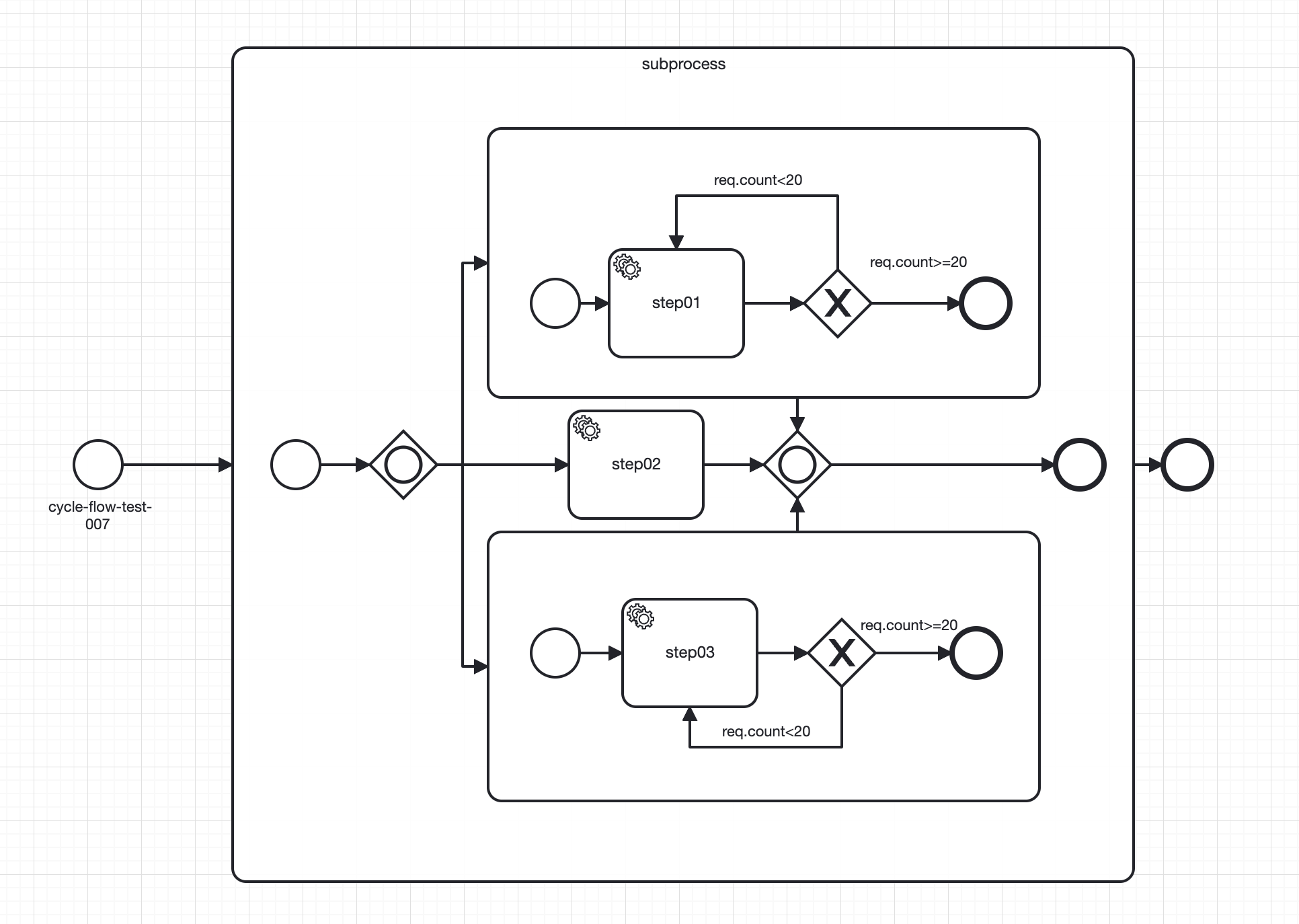
🟢 回环流程的限制针对的是一个流程,可以是主流程也可以是子流程。可以在子流程中定义需要执行的回环逻辑,然后再拼接入主流程
🟢 回环子流程可以支持嵌套和串联
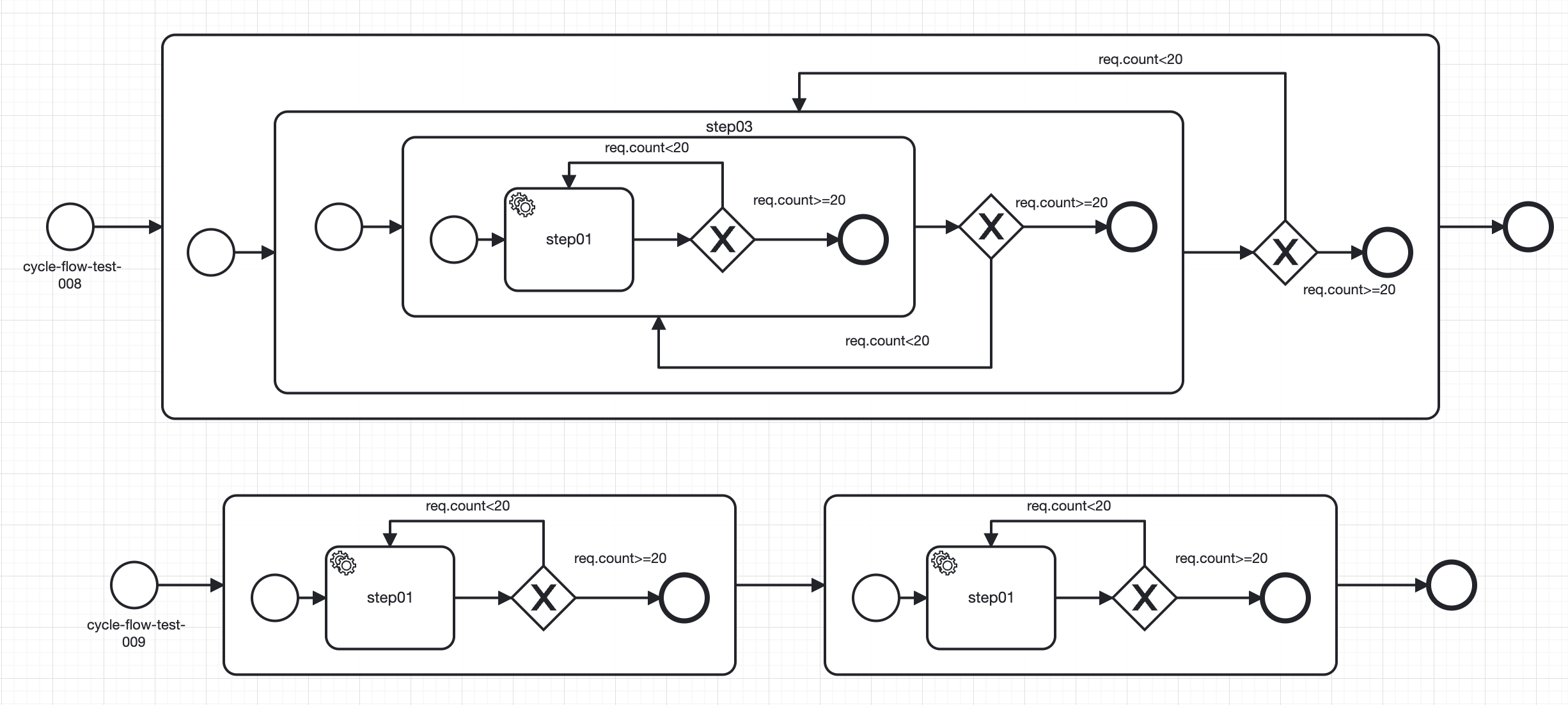
# 2.7 节点控制
# 2.7.1 条件表达式
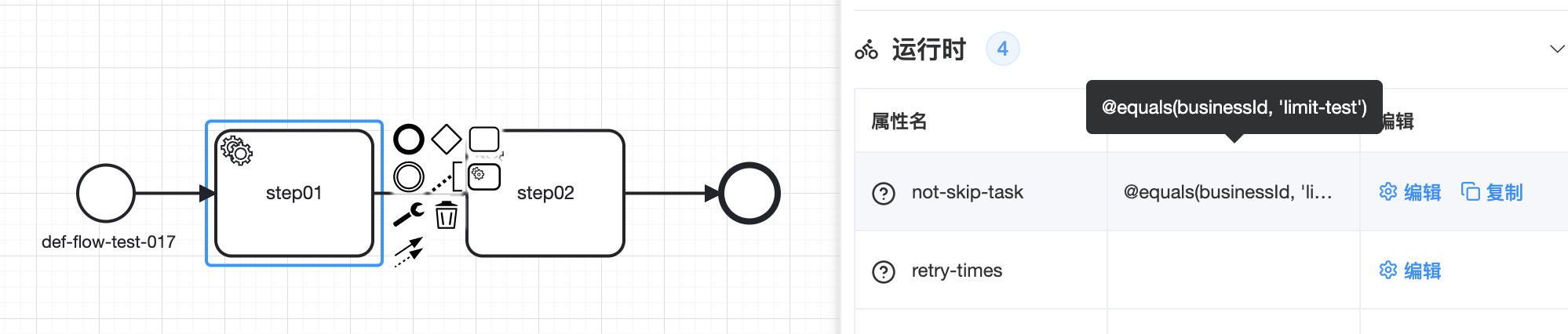
🟢 可以通过配置not-skip-task属性来控制是否跳过当前服务节点继续向下执行。默认为空,不跳过
🟢 条件表达式格式同上
# 2.7.2 允许服务为空
TIP
默认情况下在配置文件中定义一个节点时,程序中必须要有一个服务节点方法与之相对应,否则容器在启动的时候就会报错。这个限制可以通过服务节点配置来绕过
在程序中缺失与服务节点相对应的方法时,会出现两种情况的报错:
// 报错一
[K1040004] No available TaskService matched! service task identity: SERVICE_TASK:[id: Activity_0ph90s5, name: 减法计算, component: calculateService, service: minusCalculate2]
// 报错二
[K1030002] TaskComponent cannot be empty! identity: SERVICE_TASK:[id: Activity_0ph90s5, name: 减法计算, component: null, service: minusCalculate2]
2
3
4
5
🟢 服务节点在同时定义了task-component和task-service两个属性时,如果在程序中没有与之相对应的服务节点方法,启动时会出现报错一
🟢 如果服务节点只定义了task-service一个属性的话,如果没有与之相对应的服务节点方法,启动时会出现报错二
可通过节点设置:allow-absent=true,来解决上面的问题。该属性表示:允许服务节点在程序中找不到与之对应的服务节点方法。找不到时不会报错,会跳过继续执行
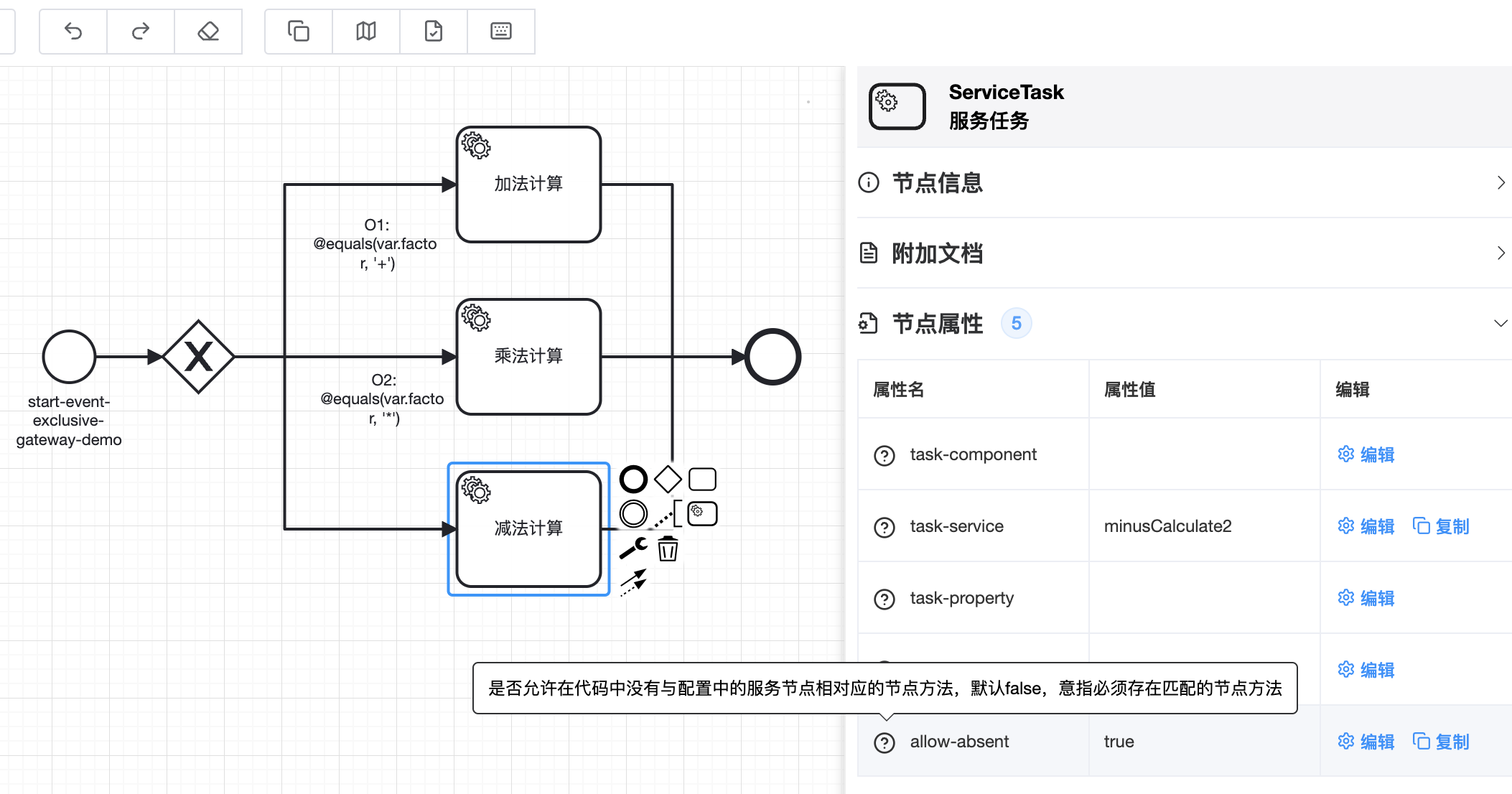
# 2.7.3 节点限流
TIP
框架提供了默认和可扩展的限流器组件,用以对服务节点进行限流
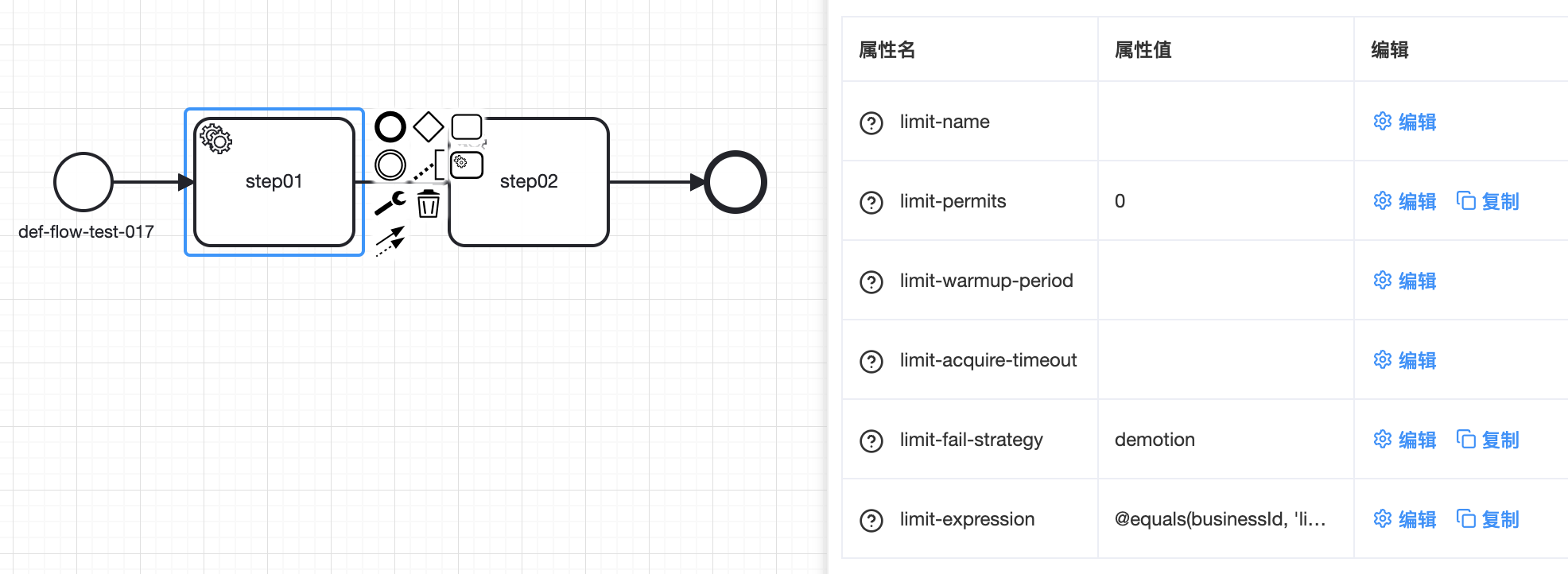
🟢 limit-name:当前服务节点及指令使用的限流器名称,默认值:local_single_node_rate_limiter 代表使用框架默认的本地单实例限流器,支持定制化
🟢 limit-permits:当前服务节点及指令运行过程中每秒可获得的令牌数量,支持小数,默认值:-1 代表不限流,设置为 0 时代表熔断当前服务节点
🟢 limit-warmup-period:当前服务节点及指令限流器生效前的预热时间,单位ms,默认值:0 代表无预热
🟢 limit-acquire-timeout:当前服务节点及指令运行过程中获取令牌的最大等待时长,单位ms,默认值:0 代表不等待
🟢 limit-fail-strategy:当前服务节点及指令运行过程中获取令牌失败后所执行的策略,支持定制化。框架默认提供了以下三种策略:
🔷 exception 默认值,被限流后抛出异常
🔷 demotion 执行服务节点降级方法(如果配置了)
🔷 ignore 跳过当前节点继续向下执行
🟢 limit-expression:当前服务节点及指令限流器是否生效的条件表达式,默认为空,代表直接生效
自定义扩展:
🟢 扩展限流器:创建实现NodeRateLimiter接口的实例并放到Spring中容器中,实现可参考LocalSingleNodeRateLimiter
🟢 扩展限流策略:创建实现FailAcquireStrategy接口的实例并放到Spring容器中,实现可参考已提供的三种策略
# 2.7.4 设置超时时间
TIP
框架允许通过设置服务节点的超时时间参数,来规定当前服务节点方法被允许执行的最大时长
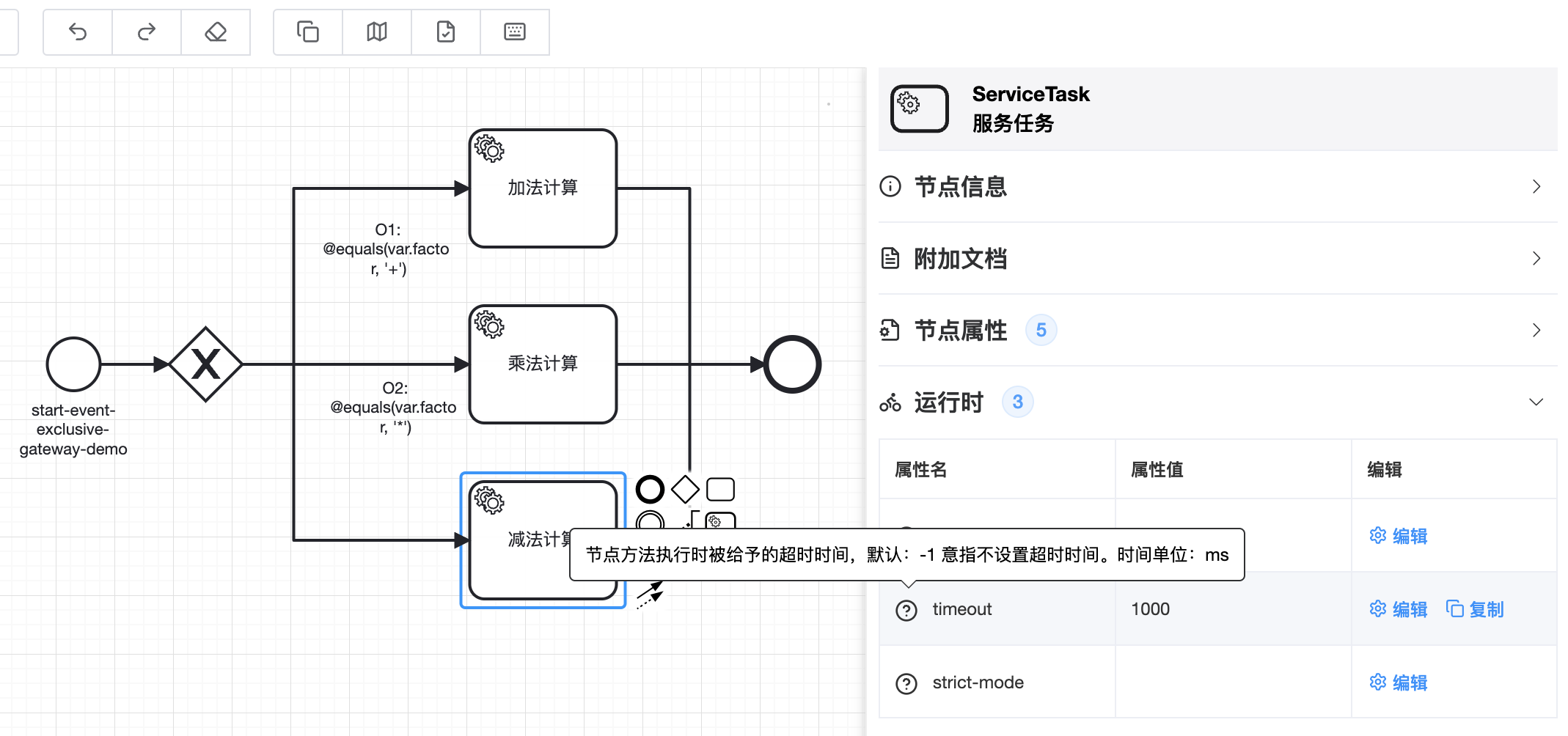
🟢 超时时间的单位是ms,默认值-1代表不设置超时时间
🟢 除配置文件外还可以通过编码的方式定义节点方法的超时时间@TaskService(invoke = @Invoke(timeout = 1000))
🟢 配置文件、代码中同时指定超时时间属性时,已配置文件中的时间为准,代码定义的值将会被忽略
# 2.7.5 节点异常重试
TIP
服务节点方法执行异常或者超时后,可以通过指定异常重试次数来重新执行目标方法
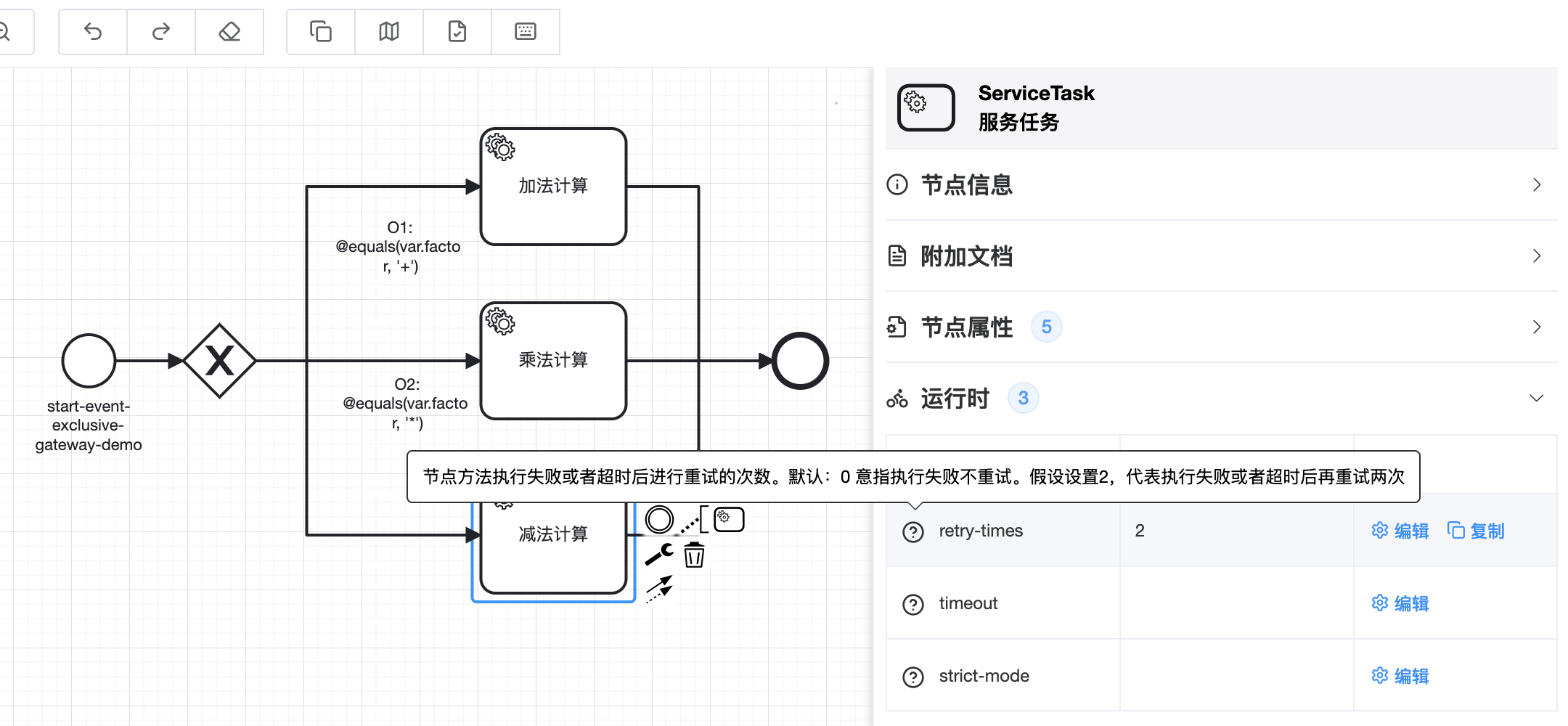
🟢 服务节点执行失败时默认重试次数为0代表不重试。假设当重试次数被设置成2时,代表如果执行失败,将进行2次重试。最大执行次数是3次
🟢 除配置文件外还可以通过编码的方式定义节点方法的异常重试@TaskService(invoke = @Invoke(retry = 2))
🟢 流程配置中也可指定服务节点失败重试次数属性,流程配置指定后,注解方式将会失效
🟢 超时时间、重试次数两个属性一起使用时需要注意一下两者叠加起来的时间是否在允许的范围内
🟢 @Invoke注解中除了retry这个属性外,还有两个属性是和重试次数联用的
🔷 retryIncludeExp:抛出异常包含指定异常时,进行重试。默认情况下列表为空,任何异常都将重试
🔷 retryExcludeExp:抛出异常不包含指定异常时,进行重试。默认情况下列表为空,任何异常都将重试
# 2.7.6 节点异常降级
TIP
服务节点执行失败或超时后,并且未设置重试次数或者重试也失败时。如果设置了降级方法,此时降级方法将会被执行
定义服务节点方法和降级方法
@NoticeResult
@TaskService(invoke = @Invoke(retry = 2, demotion = "pr:calculateService@calculateErrorDemotion"))
public int calculateError() {
return 1 / 0;
}
/**
* 定义降级方法
*/
@TaskService
public int calculateErrorDemotion() {
return 10;
}
2
3
4
5
6
7
8
9
10
11
12
13
定义流程
@Bean
public ProcessLink testCalculateErrorDemotionProcess() {
StartProcessLink processLink = StartProcessLink.build(ProcessConfig::testCalculateErrorDemotionProcess);
processLink.nextService(CalculateService::calculateError).build().end();
return processLink;
}
2
3
4
5
6
测试执行
@Test
public void testCalculateErrorDemotion() {
// 构造request
StoryRequest<Integer> fireRequest = ReqBuilder.returnType(Integer.class)
.trackingType(TrackingTypeEnum.SERVICE_DETAIL).startProcess(ProcessConfig::testCalculateErrorDemotionProcess)
.build();
TaskResponse<Integer> result = storyEngine.fire(fireRequest);
Assert.assertTrue(result.isSuccess());
Assert.assertEquals((int) result.getResult(), 10);
}
2
3
4
5
6
7
8
9
10
实例中通过demotion = "pr:calculateService@calculateErrorDemotion"指定服务节点执行失败或超时后的降级方法。异常发生后会根据表达式从容器中找到对应的服务节点执行。如果demotion配置格式有问题,或者降级使用的服务节点方法未找到时降级策略将不会生效
降级方法表达式格式是:pr:{task-component}@{task-service}或者pr:{task-component}@{task-service}@{ability}。ability是@TaskService注解的属性,用来表示服务节点的子能力,后面RBAC模式时会详细介绍
🟢 可以使用task-demotion属性在流程配置中指定降级方法
🟢 框架默认提供了一个可供直接使用的降级方法:pr:global-service-demotion@demotion
🟢 降级表达式举例:
🔷 pr:risk-control@check-img 服务组件名是 risk-control 且节点方法名是 check-img
🔷 pr:risk-control@check-img@triple 服务组件名是 risk-control 且节点方法名是 check-img 且能力点名是 triple
# 2.7.7 忽略执行时异常
TIP
默认情况下,服务节点方法在执行失败或者超时时程序会抛出异常结束整个流程。框架提供了配置属性可以屏蔽当前服务节点方法的运行时异常继续执行下一个节点
可通过给节点增加:strict-mode=false属性,来关闭服务节点的严格模式(并行网关也有一个严格模式,要分清两者作用的不同),跳过异常,让流程得以继续向下执行
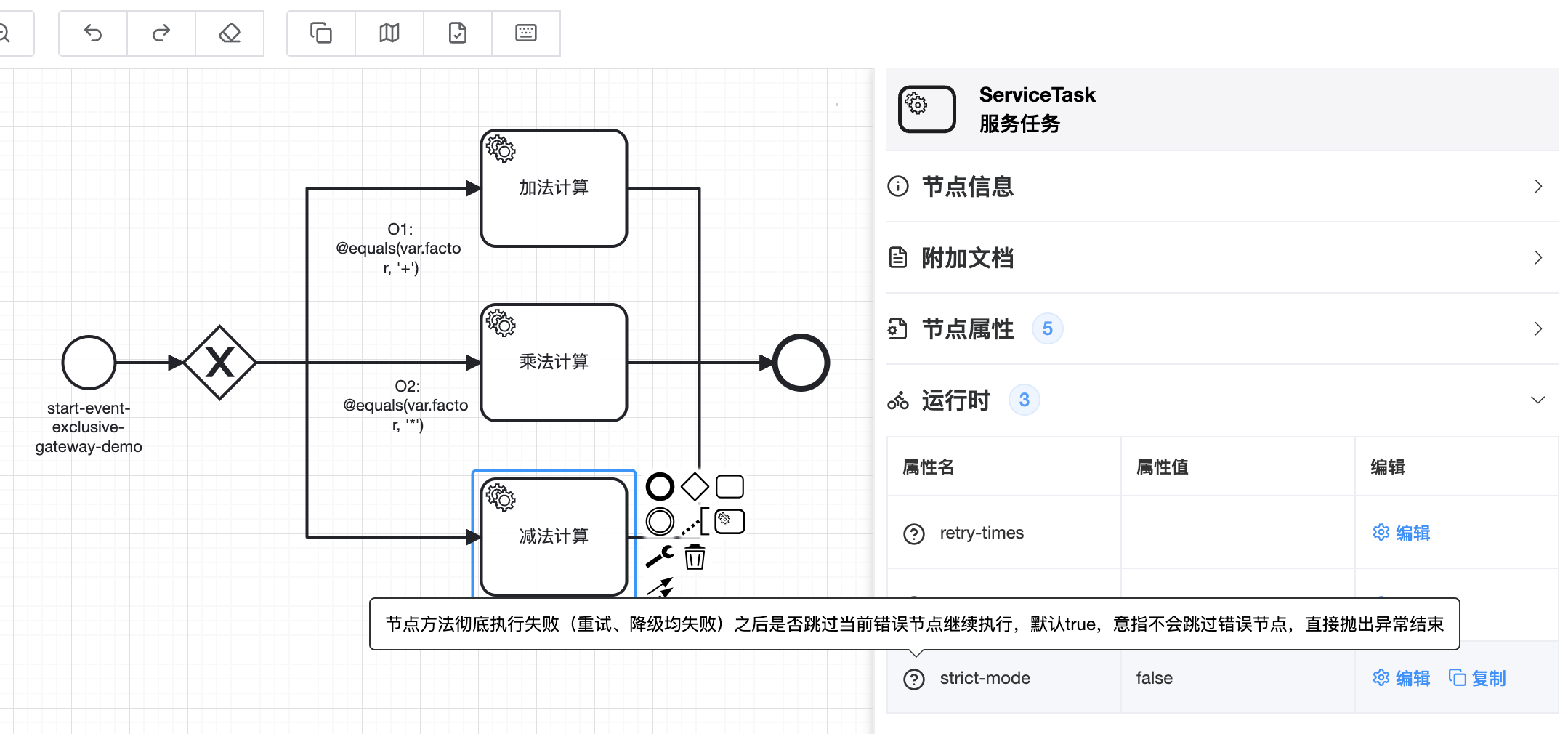
🟢 除配置文件外还可以通过编码的方式定义节点方法的非严格模式@TaskService(invoke = @Invoke(strictMode = false))
🟢 配置文件、代码两者同时为严格模式时才会是严格模式,有任一个是非严格模式时,任务就是非严格模式。默认情况下两种都是严格模式
# 2.7.8 各机制生效顺序
TIP
以上介绍了多种节点控制的手段,要想合理使用的话,就需要了解各个机制的生效顺序及前后关联
1️⃣ 通过表达式(如果有)判断是否跳过当前服务节点不执行
2️⃣ 如果配置了限流规则,判断节点是否被限流,如果被限流将执行失败策略,反之继续向下执行
3️⃣ 如果配置了大于-1的超时时间,目标方法调用会存在超时时间的限制,给定时间内未成功返回会抛出超时异常
4️⃣ 服务节点方法在出现超时异常或执行异常时,会判断是否设置了重试次数,如果重试次数大于0,会进行相应次数的重试操作
5️⃣ 未指定重试次数或指定次数的重试都失败后,如果指定了降级方法,则会在此时调用降级方法
6️⃣ 以上调用全部都失败后,会判断当前服务节点是否为严格模式,如果是非严格模式,异常将会被忽略,流程会继续向下执行
# 2.8 流程遍历
TIP
在日常研发工作中,不难遇到一些需要对数据集合进行遍历处理的工作。比如集合中的每项数据依次使用给定的计算规则进行遍历计算。再比如电商场景中订单列表、商品列表、SKU列表等,在返回给前端界面渲染展示前都需要对列表的每一项进行相关资源的加载计算和赋值。在以上场景中,都有一个相同的特点,就是虽然计算规则复杂且场景多样,但是作用到集合中每项数据的规则都是一致且统一的
Kstry提供能力:对选定集合中的每一项数据在服务节点、子流程两个维度进行指定规则的加工计算
# 2.8.1 遍历属性配置
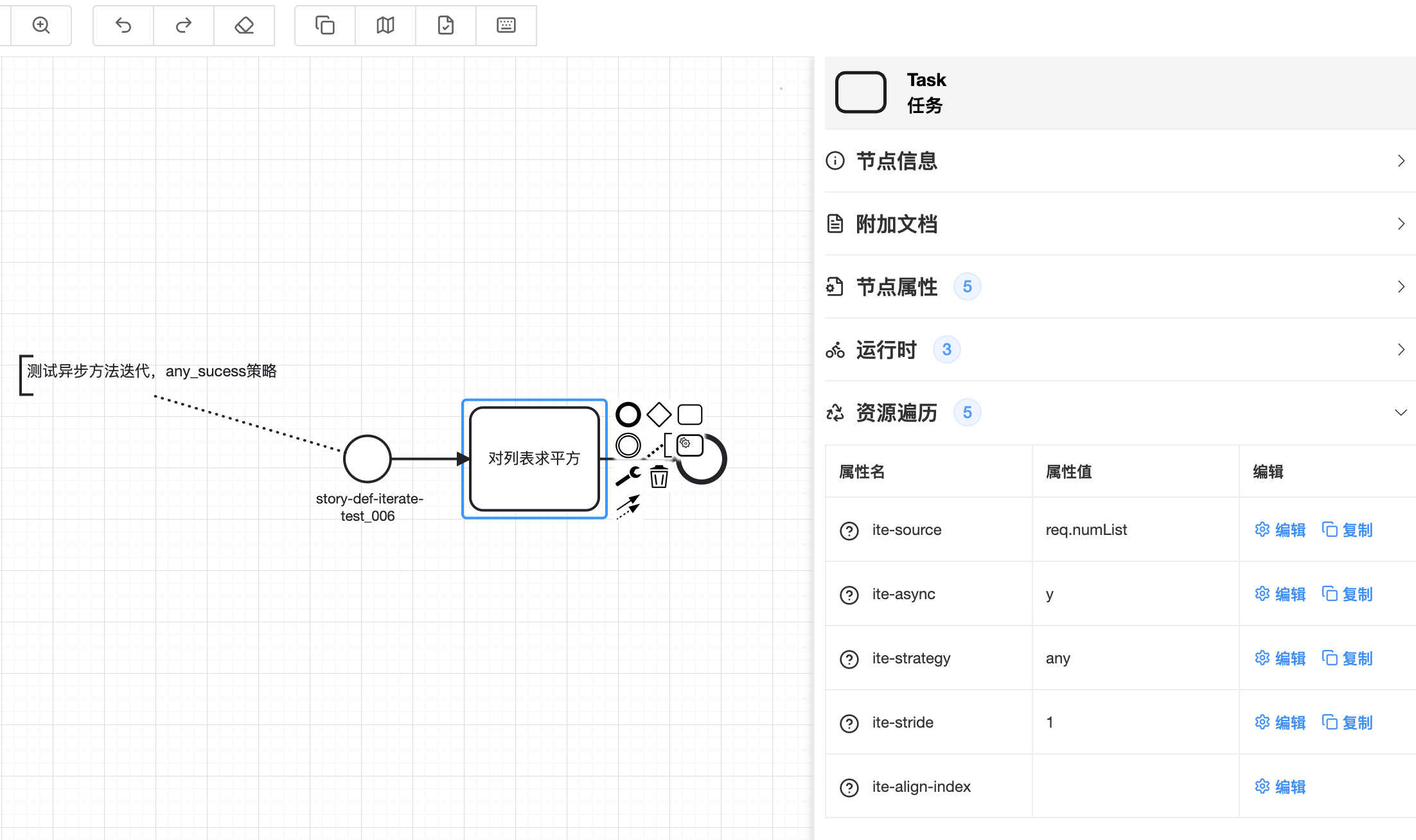
ite-source: 指定数据集合资源的位置,格式为正常的取值表达式,如:req.numList。甚至还可以对集合中对象的某个字段做遍历,比如:$.studyExperienceList[*].classId,此时需要注意最前面的$一定要有,其取值逻辑可以参考fastjson的JSONPath使用
🟢 只有指定正确格式的ite-source属性,才会开启遍历动作
🟢 ite-source指定的资源一定是实现java.lang.Iterable接口或者数组格式,否则不会开启遍历动作
🟢 如果指定的集合资源未找到,则对应的服务节点或者子任务将直接跳过不再执行
ite-strategy: 指定遍历策略,有三个取值
🟢 all:不指定时的默认策略,集合中全部元素在遍历中都需要获取到正确的结果,只要有一个不满足会抛出异常,是否结束流程受strict-mode影响。
🟢 best:集合中全部元素进行遍历,尽量多的拿到正确结果,如果有数据项执行期间抛出异常,流程会忽略异常不会结束
🟢 any:集合中只要有一项数据执行成功,就会结束遍历过程
ite-async: 遍历动作是否并发进行
ite-stride: 遍历步长。用来指定每次遍历时从集合或者数组中拿取多少个元素。默认为1代表逐个遍历。最后一次遍历集合中数据项数量小于步长时会全部返回
ite-align-index: 迭代时,是否将返回值、入参两集合中的索引进行一一对应,比如:入参5个元素,经过处理后出参有三个元素有值,另外两个为null。选择出入参对齐,返回结果将是包含有null的5个元素的List,反之将返回包含有三个结果元素的List。默认false意指不进行索引对齐
TIP
定义服务节点方法时,以上属性均可以在@TaskService注解中指定
@TaskService(
iterator = @Iterator(sourceScope = ScopeTypeEnum.VARIABLE, source = "", async = true, strategy = IterateStrategyEnum.BEST_SUCCESS)
)
2
3
代码、配置文件均指定同一值时,以配置文件中的值为准
# 2.8.2 遍历服务节点
对集合中的一组数据求平方
定义服务节点方法
@TaskComponent(name = "calculate-service")
public class CalculateService {
/**
* 求平方再放回
*/
@TaskService(name = "batch-square2")
@NoticeScope(target = {"squareResult", "a"}, scope = {ScopeTypeEnum.RESULT, ScopeTypeEnum.STABLE})
public List<Integer> batchSquare2(ScopeDataOperator dataOperator, IterDataItem<Integer> data) throws InterruptedException {
// 迭代项可以从dataOperator中取,如果步长>1时,获取到的将是List类型
Optional<List<Integer>> iterDataItem = dataOperator.iterDataItem();
Assert.assertEquals(3, data.getSize());
// 也可以将IterDataItem对象放到入参上,迭代项会自动被注入到这个对象中
AssertUtil.equals(iterDataItem.map(CollectionUtils::size).orElse(null), Optional.of(data.getDataList()).map(CollectionUtils::size).orElse( null));
return data.getDataList().stream().map(i -> i * i).collect(Collectors.toList());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
IterDataItem中有以下几个参数:
🟢 data:步长为1时,拿到迭代中的每一个遍历项
🟢 dataList:步长>1时,拿到迭代中的每一个遍历项集合
🟢 batchItem:步长是否为1。步长为1时返回false,步长>1时返回true
🟢 index:遍历中的每一项所在原来集合中的位置索引,从0开始
🟢 size:最终需要迭代的次数
如果在遍历节点中设置了超时时间、重试次数、降级方法等,会对每一个遍历项生效,节点的严格模式属性对整个遍历动作生效。
注意:
当遍历步长>1时,服务节点方法返回值需要是List类型
# 2.8.3 遍历子流程节点
如果一个集合中的数据都需要进行某些操作时,可以考虑将这些操作定义成子流程,然后指定子流程的遍历属性来依次处理这个集合中数据
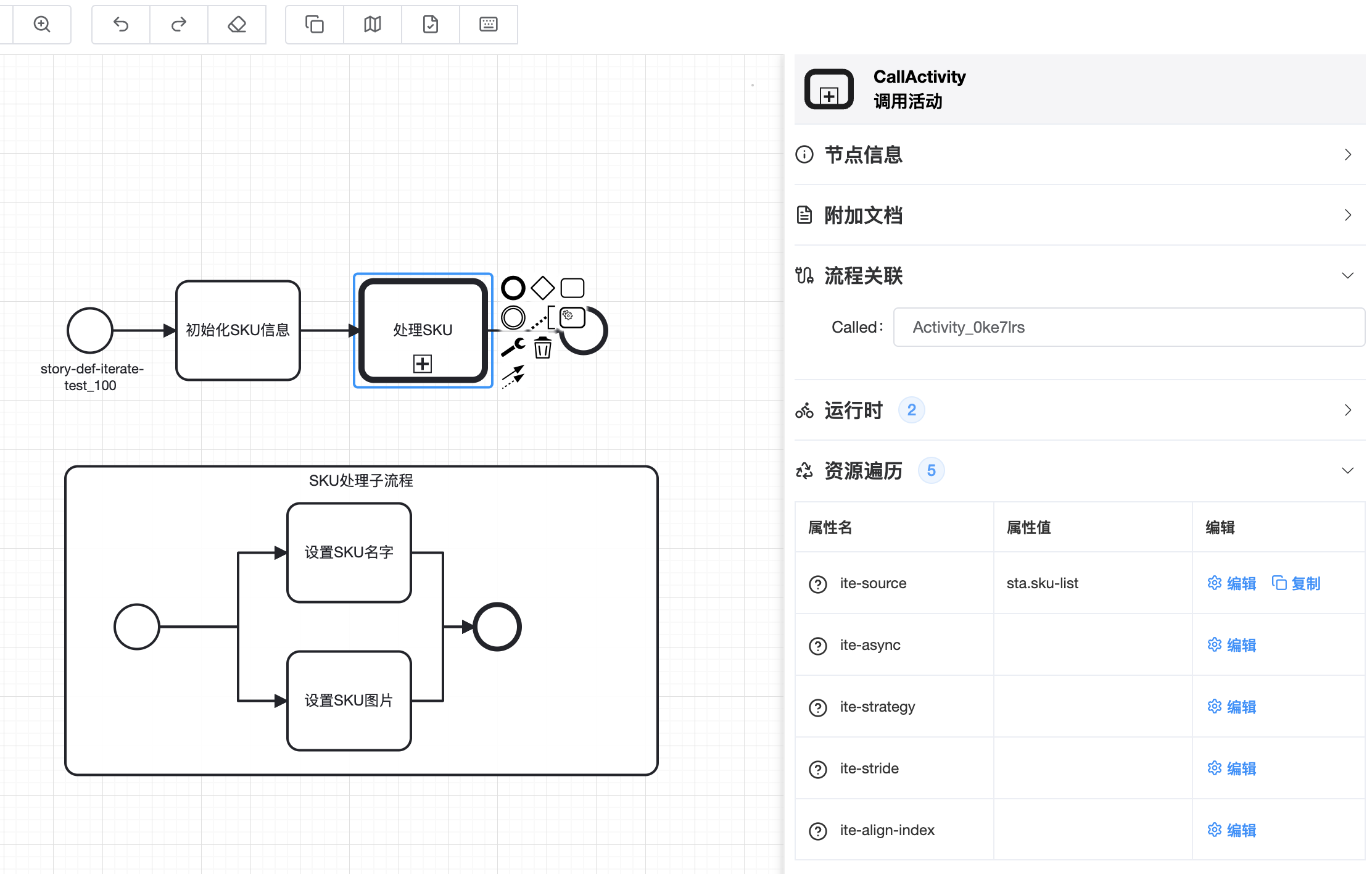
🟢 子流程遍历属性可以设置在子流程上面对全部调用子流程的主流程都生效,也可以设置在调用子流程的CallActivity节点上,仅对当前主流程生效
🟢 框架中子流程遍历属性的实现原理,是在流程解析时将子流程上遍历相关的属性设置到了流程中的每一个服务节点上。所以实际的执行效果并不是流程的一遍遍执行。而是流程中的A节点全部遍历执行完之后,再进行B节点的遍历执行依次类推。
# 2.9 服务节点拦截器
TIP
框架提供了服务节点拦截器,用来对流程中需要执行的服务节点进行拦截和控制
拦截器定义
@Slf4j
@Component
public class ServiceNodeInterceptor implements TaskInterceptor {
/**
* 接口有默认行为,可以不实现该方法
*/
@Override
public int getOrder() {
return Ordered.HIGHEST_PRECEDENCE;
}
/**
* 接口有默认行为,可以不实现该方法
*/
@Override
public boolean match(IterData iterData) {
ScopeDataOperator dataOperator = iterData.getDataOperator();
return true;
}
@Override
public Object invoke(Iter iter) {
ServiceNodeResource serviceNode = iter.getServiceNode();
ScopeDataOperator dataOperator = iter.getDataOperator();
Role role = iter.getRole();
Object data = iter.next();
log.info("ComponentName: {}, ServiceName: {}, AbilityName: {}, data: {}", serviceNode.getComponentName(), serviceNode.getServiceName(), serviceNode.getAbilityName(), data);
return data;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
🟢 创建实现了TaskInterceptor接口的类实例并放入Spring容器中,服务节点拦截器便会生效
🟢 TaskInterceptor接口提供以下三个方法:
🔷 getOrder():用来指定拦截器列表顺序,接口有默认实现可以不重写,默认返回0
🔷 match(IterData iterData):用来判断当前拦截器是否生效。默认情况下,服务节点拦截器对全部服务节点生效,该方法可以过滤掉无需生效的拦截器。接口有默认实现可以不重写,默认返回:true
🔷 invoke(Iter iter):拦截器实际生效的方法。提供Iter入参,可以凭此对象执行下一个拦截器或目标节点,获取Role、ScopeDataOperator、ServiceNodeResource
🟢 服务节点拦截器在节点策略动作的最外层。也就是说出现重试、降级、迭代等动作时服务节点会被执行多次,但是拦截器只会执行一次。如果需要在服务节点方法被调用时进行拦截,可以使用Spring AOP,因为类组件本身就是Spring中的实例
# 2.10 自定义指令
TIP
一些场景中需要对数据进行操作比如排序、过滤、计算等。这些操作服务节点可以完成,但它一般是以满足业务动作为目标,用来定义完成这种洗数据的工作太过于繁重,然而数据加工又不得不做。框架提供了自定义指令的功能,可以用来定义通用的工具,在流程中直接使用
自定义指令是在服务节点的基础上创建的,它实际上就是一个服务节点。只是此时的服务节点提供了一套更通用更便捷的使用方式,被定义用来解决一些与业务无关的通用性问题。这种更通用更便捷的使用方式就是自定义指令。
# 2.10.1 定义指令
用来对StoryBus中的集合进行排序
@TaskComponent(name = "InstructService")
public class InstructService {
@TaskInstruct(name = "sort")
@TaskService(name = "instruct-service-sort")
public void sort(InstructContent instructContent, ScopeDataOperator operator) {
SortContent sortContent = JSON.parseObject(instructContent.getContent(), SortContent.class);
Optional<Object> dataOptional = operator.getData(sortContent.getSource());
if (!dataOptional.isPresent() || !(dataOptional.get() instanceof List)) {
return;
}
List<?> list = (List<?>) dataOptional.get();
if (sortContent.asc) {
list.sort(Comparator.comparing(o -> {
try {
return (Comparable) PropertyUtils.getProperty(o, sortContent.getSortFieldName());
} catch (Exception e) {
return null;
}
}));
} else {
list.sort(Comparator.comparing(o -> {
try {
return (Comparable) PropertyUtils.getProperty(o, sortContent.getSortFieldName());
} catch (Exception e) {
return null;
}
}).reversed());
}
operator.setData(sortContent.getTarget(), list);
}
@Data
public static class SortContent {
/**
* 要排序数据的位置
*/
private String source;
/**
* 根据对象的哪个字段来排序
*/
private String sortFieldName;
/**
* 排序后的集合放在什么地方
*/
private String target;
/**
* 是否是升序
*/
private boolean asc;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
🟢 如果不考虑@TaskInstruct(name = "sort"),仅仅是定义了一个名字为instruct-service-sort的服务节点,加上@TaskInstruct就是自定义指令
🟢 @TaskInstruct有一个name属性,用来定义指令的名称。在BPMN配置文件中使用指令时名称前面需要加c-,比如上面的例子就是c-sort
🟢 InstructContent参数用来获取指令名称和内容。无需增加任何注解,直接使用即可
# 2.10.2 使用指令
TIP
假设对一组商品标签进行排序
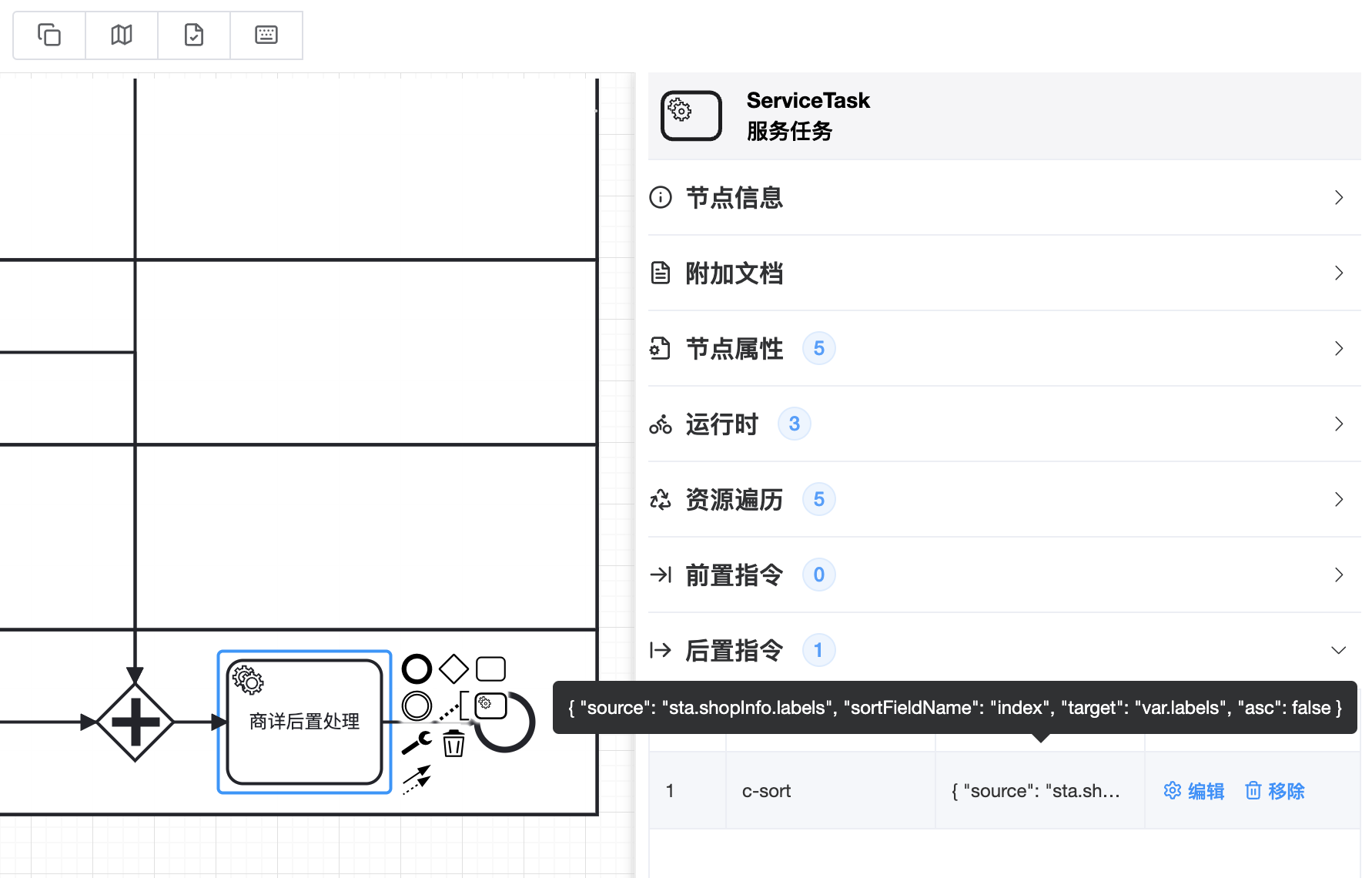
指令名称是c-sort,内容是:
{
"source": "sta.shopInfo.labels", // 要排序数据的位置
"sortFieldName": "index", // 根据对象的哪个字段来排序
"target": "var.labels", // 排序后的集合放在什么地方
"asc": false // 是否是升序
}
2
3
4
5
6
🟢 上面例子中简单定义服务节点的指令名称和值,其他的并未定义
🟢 服务节点支持同时配置指令和服务节点名称,并且同一个服务节点支持同时配置多个不同指令
🟢 c-开头的指令如果和服务节点名称同时存在,默认会先执行名称对应的服务节点再执行指令。如果执行顺序要反过来需要在c-前面加^,例如:^c-sort
🟢 包含网关、排他网关也支持同时配置一个或多个指令,定义的指令会在网关之前执行,使用场景是网关前面定义指令对数据进行加工,网关后面再跟条件表达式进行路由决策
注意:
代码方式定义流程时是不支持增加^前缀来改变指令和节点方法执行顺序的
# 2.11 脚本指令
TIP
Kstry服务节点支持JS脚本指令,实现方式就是自定义指令。如果当下的脚本引擎或者逻辑不满足现状的话,可以使用自定义指令进行定制化脚本引擎的开发
# 2.11.1 实现脚本指令
@TaskInstruct(name = "jscript")
@TaskService(name = "js-script-instruct")
public void instruct(InstructContent instructContent, ScopeDataOperator scopeDataOperator) {
if (StringUtils.isBlank(instructContent.getContent())) {
return;
}
JsScriptProperty property = null;
if (scopeDataOperator.getTaskProperty().isPresent()) {
try {
property = JSON.parseObject(scopeDataOperator.getTaskProperty().get(), JsScriptProperty.class);
} catch (Exception e) {
LOGGER.warn("[{}] js script property parsing exception. instruct: '{}{}', property: {}", ExceptionEnum.SCRIPT_PROPERTY_PARSER_ERROR.getExceptionCode(),
BpmnElementProperties.SERVICE_TASK_TASK_INSTRUCT, instructContent.getInstruct(), scopeDataOperator.getTaskProperty().orElse(StringUtils.EMPTY), e);
}
}
String invokeMethodName = "invoke";
String script = instructContent.getContent();
try {
if (property != null && StringUtils.isNotBlank(property.getInvokeMethod())) {
invokeMethodName = property.getInvokeMethod();
} else {
script = GlobalUtil.format(DEFAULT_FUNCTION, invokeMethodName, script);
}
LOGGER.debug("invoke js script. instruct: '{}{}', script: {}, property: {}",
BpmnElementProperties.SERVICE_TASK_TASK_INSTRUCT, instructContent.getInstruct(), script, scopeDataOperator.getTaskProperty().orElse(StringUtils.EMPTY));
ScriptEngine jsEngine = new ScriptEngineManager().getEngineByName("javascript");
Bindings bind = jsEngine.createBindings();
bind.put("ksta", scopeDataOperator.getStaScope());
bind.put("kvar", scopeDataOperator.getVarScope());
bind.put("kreq", scopeDataOperator.getReqScope());
bind.put("kres", scopeDataOperator.getResult().orElse(null));
jsEngine.setBindings(bind, ScriptContext.ENGINE_SCOPE);
jsEngine.eval(script);
Object result = ((Invocable) jsEngine).invokeFunction(invokeMethodName);
if (result != null && property != null && !StringUtils.isAllBlank(property.getReturnType(), property.getResultConverter())) {
result = typeConverterProcessor.convert(property.getResultConverter(), result, Optional.ofNullable(property.getReturnType()).filter(StringUtils::isNotBlank).map(rt -> {
try {
return Class.forName(rt);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}).orElse(null)).getValue();
}
if (property != null && CollectionUtils.isNotEmpty(property.getReturnTarget())) {
for (String target : property.getReturnTarget()) {
boolean setRes = scopeDataOperator.setData(target, result);
if (!setRes) {
LOGGER.warn("invoke js script set result fail. instruct: '{}{}', target: {}, result: {}",
BpmnElementProperties.SERVICE_TASK_TASK_INSTRUCT, instructContent.getInstruct(), target, result);
}
}
}
LOGGER.debug("invoke js script success. instruct: '{}{}', result: {}", BpmnElementProperties.SERVICE_TASK_TASK_INSTRUCT, instructContent.getInstruct(), result);
} catch (Throwable e) {
throw ExceptionUtil.buildException(e, ExceptionEnum.SCRIPT_EXECUTE_ERROR, GlobalUtil.format("js script execution exception! instruct: '{}{}', property: {}, script: \n{}",
BpmnElementProperties.SERVICE_TASK_TASK_INSTRUCT, instructContent.getInstruct(), scopeDataOperator.getTaskProperty().orElse(StringUtils.EMPTY), script));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
以上为使用自定义指令实现支持的服务节点脚本功能的源码,可直接使用默认脚本能力,也可作为参考实现自己的脚本引擎
# 2.11.2 默认脚本功能
下图是在服务节点上定义的一个脚本指令:
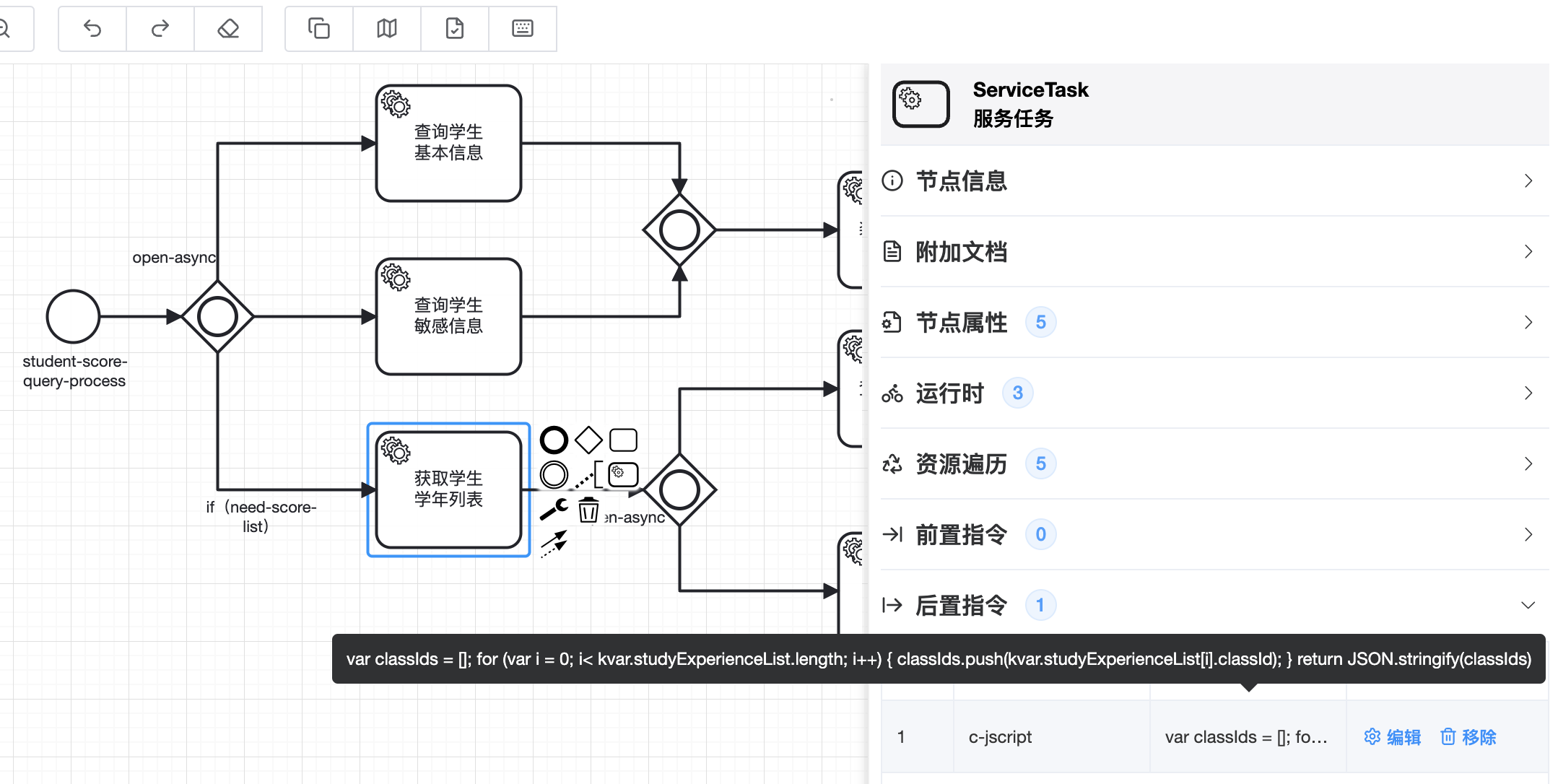
🟢 脚本指令需要指定脚本名称c-jscript,此名称是固定的,指令内容不能为空否则脚本不生效
🟢 如果指令和服务节点名称同时存在,并且想要在节点方法之前执行,可以在指令名称前加^,这也是自定义指令的功能
🟢 在服务节点或者网关上可以使用task-property来指定脚本属性,默认脚本支持的属性如下:
{
"result-converter": "object_to_long_list",
"return-target": "var.classIds"
}
2
3
4
🔷 invoke-method:指定脚本方法名称。默认无需设置,此时直接写脚本逻辑即可,如果该字段不为空,脚本内容需定义成方法格式如下,此时"invoke-method": "inv":
function inv(){
var classIds = [];
for (var i = 0; i< kvar.studyExperienceList.length; i++)
{
classIds.push(kvar.studyExperienceList[i].classId);
}
return JSON.stringify(classIds)
}
2
3
4
5
6
7
8
🔷 return-type:脚本执行完之后结果的返回类型
🔷 return-target:脚本执行完之后最终的结果被放到StoryBus的什么位置,支持设置多个
🔷 result-converter:指定类型转换器,将脚本拿到的结果转换成需要的类型
🟢 包含网关、排他网关也支持配置自定义指令,脚本指令也是指令,所以也是支持的
注意:
高版本JDK不支持JS引擎获取,new ScriptEngineManager().getEngineByName("javascript");会得到空值,此时需要在项目中加入依赖:
<dependency>
<groupId>org.openjdk.nashorn</groupId>
<artifactId>nashorn-core</artifactId>
<version>15.3</version>
</dependency>
2
3
4
5
# 2.12 代码方式定义流程
TIP
BPMN文件虽然有非常优秀的可视化特点,但是也有一些不足之处,比如ide中点击定义在配置文件中的服务节点无法快速定位到具体方法、无法识别自定义协议的流程文件等。Kstry提供代码定义流程的方式来平衡这些问题。
框架提供ProcessLink作为代码方式定义流程最核心的类,它提供了众多辅助流程节点彼此间拼接的方法:
🟢 nextTask:指定下一个服务节点,类组件和服务节点名称都需要提供
🟢 nextService:指定下一个服务节点,仅需要提供服务节点名称即可。在确保服务节点名称全局唯一时使用,可以节省代码量
🟢 nextInstruct:指定下一个指令。指令是一种特殊的服务节点。
🟢 nextSubProcess:指定下一个子流程
🟢 nextExclusive:指定下一个排他网关
🟢 nextInclusive:指定下一个包含网关
🟢 nextParallel:指定下一个并行网关
🟢 joinTask:将多个任务分支进行合并
🟢 end:指定下一个结束事件
# 2.12.1 主流程定义
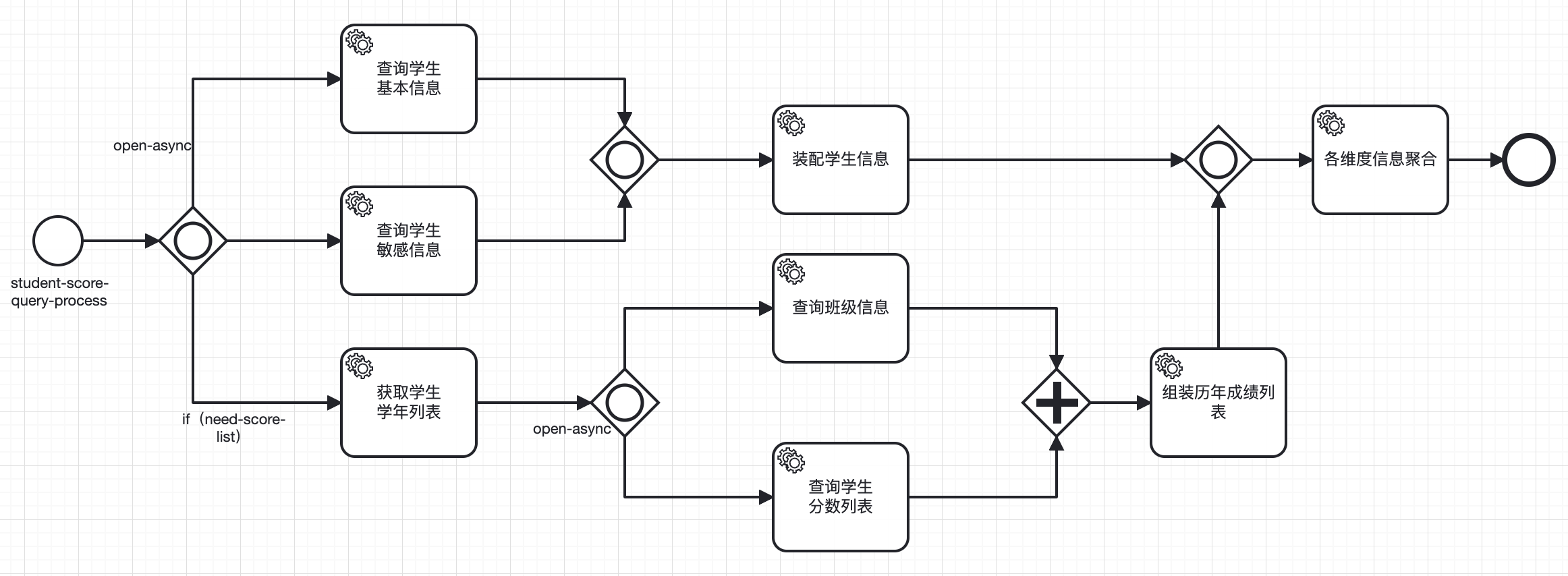
代码方式定义此流程图如下:
@Bean
public ProcessLink studentScoreQueryProcess() {
String instructContent = "var classIds = [];"
+ "for (var i = 0; i< kvar.studyExperienceList.length; i++)"
+ "{"
+ " classIds.push(kvar.studyExperienceList[i].classId);"
+ "}"
+ "return JSON.stringify(classIds)";
StartProcessLink processLink = StartProcessLink.build(DefProcess::studentScoreQueryProcess);
InclusiveJoinPoint asyncInclusive = processLink.nextInclusive(processLink.inclusive().openAsync().build());
InclusiveJoinPoint asyncInclusive2 = asyncInclusive
.nextService(Exp.b(e -> e.isTrue(ScopeTypeEnum.REQUEST, QueryScoreRequest.F.needScore)), StudentScoreService::getStudyExperienceList).build()
.nextInstruct("jscript", instructContent).name("JS脚本").property("{\"result-converter\": \"object_to_long_list\",\"return-target\": \"var.classIds\"}").build()
.nextInclusive(processLink.inclusive().openAsync().build());
processLink.inclusive().build().joinLinks(
processLink.parallel().notStrictMode().build().joinLinks(
asyncInclusive2.nextService(StudentScoreService::getClasInfoById).build(),
asyncInclusive2.nextService(StudentScoreService::getStudentScoreList).build()
).nextService(StudentScoreService::assembleScoreClassInfo).build(),
processLink.inclusive().build().joinLinks(
asyncInclusive.nextService(StudentScoreService::getStudentBasic).build(),
asyncInclusive.nextService(StudentScoreService::getStudentPrivacy).build()
).nextService(StudentScoreService::assembleStudentInfo).build()
)
.nextService(StudentScoreService::getQueryScoreResponse).build()
.end();
return processLink;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
🟢 定义ProcessLink对象,放入Spring容器中,流程在启动时就会被加载生效,这种生效方式是不支持动态变更的
# 2.12.2 子流程定义
@Bean
public SubProcessLink calculateSubProcessDemo() {
return SubProcessLink.build(ProcessConfig::calculateSubProcessDemo, link -> {
InclusiveJoinPoint inclusiveJoinPoint = link.nextInclusive(link.inclusive().openAsync().build());
link.inclusive().build().joinLinks(
inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'+'")), CalculateService::plusCalculate).build(),
inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'*'")), CalculateService::multiplyCalculate).build(),
inclusiveJoinPoint.nextService(Ex.b(e -> e.equals("var.factor", "'-'")), CalculateService::minusCalculate).build()
).end();
});
}
2
3
4
5
6
7
8
9
10
11
🟢 子流程与主流程有相似之处,定义SubProcessLink对象放入Spring容器中,子流程在启动时就会被加载生效,同样不支持动态变更
# 2.12.3 解析文件定义流程
代码定义流程看上去比BPMN可视化流程图复杂不少,为什么还要支持呢?
正如前面所说的,少量服务节点组成的流程,代码定义起来会更加方便。而更重要的一个原因则是,用代码方式定义流程可以支持任意协议的流程配置文件,可以按需解析开源或公司内部的前端流程组件,并配合Kstry完成最终的流程编排。
而框架本身,在1.1.x之后的版本里PBMN流程配置文件也是用这套API来解析的,具体可以参考Kstry源码中的实现: CamundaBpmnModelTransfer (opens new window)。在后面的动态流程配置里,这套API也是必不可少的部分
# 2.13 动态流程配置
TIP
定义路径扫描bpmn文件和创建ProcessLink实例放入Spring容器两种流程的定义方式是静态的,如果要修改只能重启应用。框架在1.1.x版本之后提供了动态获取流程配置的能力,并且动态化配置支持通过http或rpc调用、关系或者非关系型数据库查询、订阅消息队列、订阅注册中心、公司自定义存储介质查询等任意方式获取
# 2.13.1 使用动态流程
@Component
public class DynamicProcessRegister implements DynamicProcess {
@Override
public long version(String key) {
return 0;
}
@Override
public Optional<ProcessLink> getProcessLink(String startId) {
InputStream inputStream = DynamicProcessRegister.class.getClassLoader().getResourceAsStream("dynamic/goods.bpmn");
BpmnProcessParser parser = new BpmnProcessParser("动态获取流程", inputStream);
return parser.getProcessLink(startId);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
🟢 创建实现DynamicProcess接口的类实例,放入Spring容器中,动态流程组件即会生效
🟢 DynamicProcess提供两个方法:
🔷 version(String key):传入startId返回当前流程的版本号,版本号没有变化并且流程缓存没有失效时,框架不会调用getProcessLink(String startId)来获取新的流程,反之则会重新获取新的流程。流程缓存的时长是1天。修改流程后控制该方法进行版本号升级,新的流程会即刻生效。如果想要删除某个流程,升级版本号后getProcessLink(String startId)返回空即可实现
🔷 getProcessLink(String startId):根据startId获取流程配置。缓存未失效且版本未改变时该方法不会被调用。
🟢 上面代码演示的是从类路径下加载流程配置文件,通过流程解析器解析生成ProcessLink对象并返回的过程。可以根据需要从任意存储介质中获取流程配置信息
🟢 如果不需要缓存,每次都要获取最新的流程,将version(String key)的返回值设置成小于0的值即可
# 2.13.2 使用动态子流程
TIP
框架同样提供了动态获取子流程的能力
@Component
public class DynamicSubProcessRegister implements DynamicSubProcess {
@Override
public List<SubProcessLink> getSubProcessLinks() {
InputStream inputStream = DynamicSubProcessRegister.class.getClassLoader().getResourceAsStream("dynamic/goods.bpmn");
BpmnProcessParser parser = new BpmnProcessParser("动态获取流程", inputStream);
return Lists.newArrayList(parser.getAllSubProcessLink().values());
}
}
2
3
4
5
6
7
8
9
10
🟢 创建实现DynamicSubProcess接口的类实例,放入Spring容器中,动态子流程组件即会生效
🟢 动态子流程没有版本的概念,只要是获取就是最新的。获取子流程动作是在创建主流程时被触发的,可以理解成主流程和子流程共用一个版本号
# 2.13.3 动态与静态流程关系
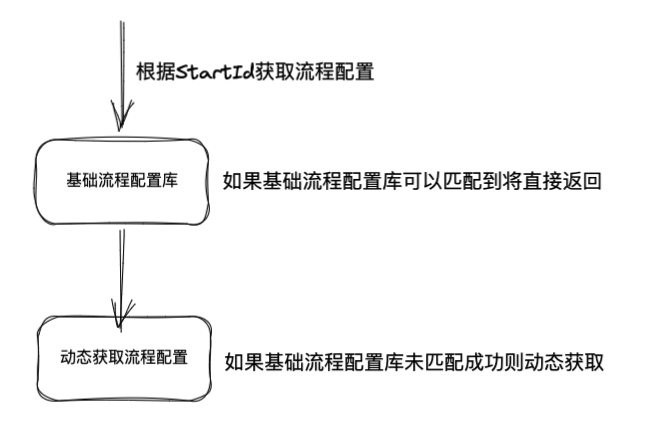
只有bpmnPath一种流程配置途径时,下面这种可视化流程图就是被定义出来的流程,也是凭此来指导程序实际线路的执行。ProcessLink出现之后,框架提供了自定义流程的能力给使用者,在1.x之后的版本中,BPMN可视化流程图也是被解析成ProcessLink对象来生效的,此时的BPMN可视化流程就作为了流程定义的一个子集而存在。更多情况下使用者可以通过编码、解析各类配置文件等方式来创建ProcessLink实例,最终交付给框架的ProcessLink实例将会作为流程定义来指导程序的执行。
Kstry提供了三种方式来定义流程配置,分别是:
🟢 【基础流程配置】指定@EnableKstry注解的bpmnPath属性来扫描指定目录下的bpmn配置文件
🟢 【基础流程配置】创建ProcessLink实例放入Spring容器中
🟢 【动态流程配置】实现DynamicProcess接口的getProcessLink方法
前面两种方式定义的流程是应用启动前就必须要定义出来的属于基础流程配置,基础流程除非应用重启否则是不允许修改的。根据startId在基础流程配置库里获取不到流程配置时最后一种方式才会生效,其获取流程配置的方式是动态的,传入startId返回ProcessLink实例,其中所需的流程配置信息可以通过http或rpc调用、关系或者非关系型数据库查询、订阅消息队列、订阅注册中心、公司自定义存储介质查询等任意方式获取。
之所以没有使用动态改变基础流程配置库的方式来实现流程的动态配置能力,有以下原因:
🟢 【安全性】流程配置可能会分重要级别,核心的流程配置是被严格管控不允许随意变更的,所以这类配置应该放在代码中不允许随意变更。如果在流程配置基础库中找到与startId相匹配的流程,动态获取部分将失效,以此来保障流程的绝对安全。即便核心流程中有部分需要动态获取的扩展逻辑,也可以用动态子流程的形式来实现。
🟢 【兼容性】动态化配置可能比较适合使用注册中心来存储维护,这样当发生变更时能快速及时通知相关应用做流程变更。但并没有一个注册中心是所有公司都使用的,除了开源产品还有公司自研,如果想要一一支持是不现实的。选用其他中间件产品也是同样的道理。所以解决这个问题的方式就是提供一个动态获取流程配置的入口,至于流程配置在什么地方获取将是因人而异的。
在流程中出现可复用或者复杂的链路片段时,就可以将这些片段抽离出来定义子流程。父流程可以通过子流程Id来引用子流程。同样也有三种方式来定义子流程,分别是:
🟢 【基础子流程配置】指定@EnableKstry注解的bpmnPath属性来扫描指定目录下的bpmn配置文件
🟢 【基础子流程配置】创建SubProcessLink实例放入Spring容器中
🟢 【动态子流程配置】实现DynamicSubProcess接口的getSubProcessLinks方法
主流程有基础和动态之分,相对应也有基础和动态子流程的存在。下图为两者结合起来时,相互之间是否允许被引用的说明:
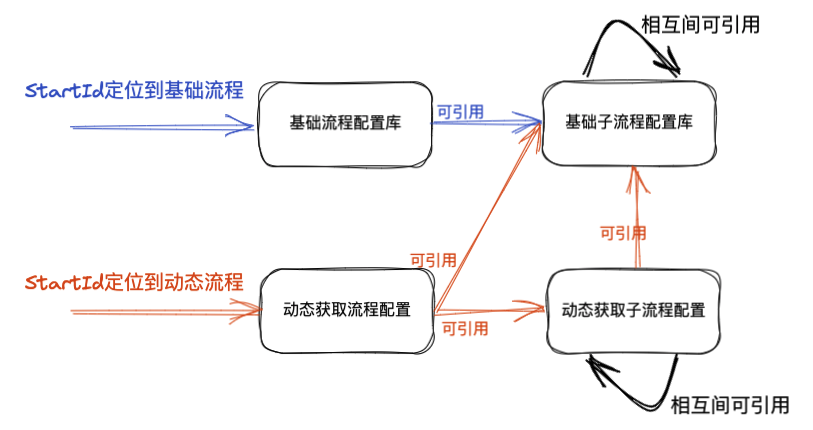
🟢 基础流程仅能引用基础子流程配置,动态流程可以引用基础子流程和动态子流程配置
🟢 两种子流程在各自的区域内可以相互引用,动态子流程中可以引用基础子流程配置,反之则不被允许
警告
子流程相互间引用时,一定不能出现环状依赖,否则会出现异常❗️❗️❗️
# 2.14 使用异步流程
TIP
流程配置中并行网关、包含网关后面的流程支持开启异步。使用JDK21+时,可以使用kstry.thread.open-virtual参数开启虚拟线程
# 2.14.1 开启异步
🟢 目前支持配置异步开启的组件有:并行网关、包含网关两种,排他网关虽然是允许有多个出度,但最终只有一个出度被执行,所以开启异步的效果不大并未支持开启异步
🟢 在网关上配置open-async=true即可开启异步功能
🟢 和普通的多线程使用方式一样,并发度太高也并非一定是好事。每开启一个新线程都要创建新的计算任务,加上线程间的上下文切换,在一些本来就耗时很短的服务节点间开启异步大多时候会得不偿失
# 2.14.2 异步化生命周期
TIP
在并行网关、包含网关上配置open-async=true属性即可开启异步流程。那么异步的开始是什么时候,结束又是在何处呢?
# 异步的开始
开始流程如下:
🟢 执行引擎检测到并行网关、包含网关上配置open-async=true属性后,会将网关后面的出度包装成异步任务,并行网关与包含网关执行策略又略显不同:
🔷 并行网关会将其后的全部出度逐一包装成异步任务,提交至线程池执行
🔷 包含网关会判断其后的出度是否有条件表达式,如果有会先解析条件表达式,将表达式结果为true和没有表达式的出度逐一包装成异步任务提交到线程池执行
🟢 提交完异步任务的线程会继续执行任务栈中的其他节点任务,不会再顾及异步网关出度及出度之后的节点,直至任务栈中没有了可执行节点时线程会归还至线程池,等待下一次被调用
🟢 线程池随机选择线程执行上述流程中创建的异步任务
# 异步的结束
什么是异步?异步就是同一时间多个线程去做了多个事情,以此来节省需要一个线程做多个事情所花费的时间。这种模式有点像算法里面的空间换取时间的味道。Kstry中什么时候结束开启后的异步任务呢?答案是多个可以同一时间执行的异步任务被聚合网关聚合后异步流程就结束了。比如:
🟢 一个流程被并行网关拆分成了两个异步任务,这两个异步任务都遇到同一聚合节点后,任务就被聚合节点归拢了,异步任务也就结束了
🟢 一个流程被并行网关拆分成了两个异步任务,两个异步任务又分别拆分出了两个异步任务,只有四个异步任务全部聚合时,才算真正意义上的异步流程结束,如下的流程定义是允许的:
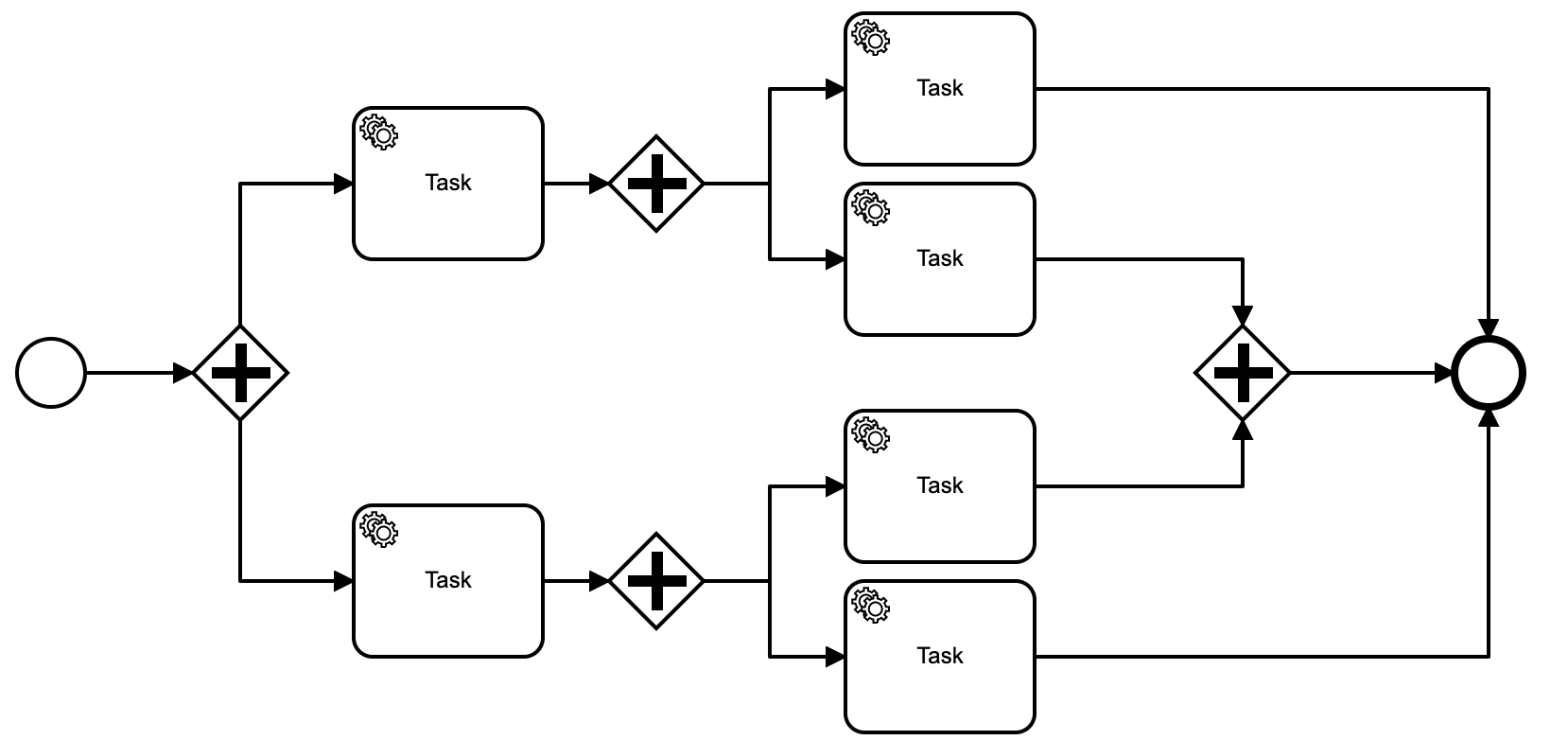
当前聚合节点的元素有:
🟢 并行网关
🟢 包含网关
🟢 结束事件
聚合节点可以随心所欲的聚合多个流程。除聚合节点外的其他节点元素,只允许接收一个入度
TIP
之所以除聚合节点外的其他节点元素,只允许接收一个入度是因为:存在多个入度时,如果这些入度是异步的就会有多个线程执行到这个聚集点,假设Task节点可以支持多入度,那么Task节点就可能被执行多次。因为Task节点不具备聚合节点的能力,不能让前面的流程停下来等待全部流程都到达后才继续。换句话说只有聚合节点才能支持多入度
# 2.14.3 线程切换钩子
TIP
框架提供了线程间切换时的回调钩子,用来传递线程切换前后的数据。钩子只对Kstry框架中执行的任务生效
使用线程切换钩子
@Component
public class SwitchHook implements ThreadSwitchHook<String> {
public static final ThreadLocal<String> ITERATOR_THREAD_LOCAL = new ThreadLocal<>();
@Override
public String getPreviousData(ScopeDataQuery scopeDataQuery) {
return ITERATOR_THREAD_LOCAL.get();
}
@Override
public void usePreviousData(String data, ScopeDataQuery scopeDataQuery) {
ITERATOR_THREAD_LOCAL.set(data);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
🟢 用ITERATOR_THREAD_LOCAL.set()在调用engine.fire()前设置一个字符串,在后面的任意节点上都可以用SwitchHook.ITERATOR_THREAD_LOCAL.get()拿到
🟢 任务执行期间发生线程切换时,实现ThreadSwitchHook接口的Spring组件就会被调用
🟢 线程切换前调用getPreviousData(ScopeDataQuery scopeDataQuery)获取到要保存的值,线程切换后再调用usePreviousData(String data, ScopeDataQuery scopeDataQuery)将切换前拿到的数据传入,用以后续的使用
🟢 ThreadSwitchHook组件出现多个时,重写getOrder()方法即可支持排序
# 2.14.4 Reactor模型
TIP
默认情况下节点方法中调用耗时长的接口时会产生工作线程的等待,从而影响整个系统的吞吐。方法支持返回Mono类型结果来释放工作线程并等待请求完成后的回调,后用回调来推进流程的下一步动作
@TaskService
@NoticeVar(target = QueryScoreVarScope.F.classInfos)
public Mono<ClassInfo> getClasInfoById(IterDataItem<Long> classIdItem) {
return Mono.fromFuture(CompletableFuture.supplyAsync(() -> {
// mock return result
Optional<Long> idOptional = classIdItem.getData();
ClassInfo classInfo = new ClassInfo();
classInfo.setId(idOptional.orElse(null));
classInfo.setName("班级" + idOptional.orElse(null));
if (classInfo.getId() == 2) {
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
return classInfo;
}, Executors.newFixedThreadPool(3)));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
🟢 除了返回值类型变为Mono类型,其他地方与默认节点方法使用方式完全相同
🟢 示例中方法会直接返回Mono对象,期间不会出现任何停滞,执行引擎拿到Mono对象之后会释放当前线程,直至Mono返回成功或失败信号后,回调动作继续驱动流程向后执行
# 2.14.5 开启虚拟线程
开启虚拟线程需要两步:
🟢 使用JDK21+启动应用
🟢 配置属性
kstry:
thread:
open-virtual: true
2
3